Construisez des pipelines de données robustes, scalables et prêts pour la production. Devenez un ingénieur data capable de concevoir, déployer et industrialiser des architectures modernes cloud & Big Data.
Le Retrieval-Augmented Generation (RAG) s'impose en 2025 comme la solution incontournable pour déployer des systèmes d'IA générative fiables en entreprise. En combinant la puissance des LLMs avec des données actualisées et vérifiées, le RAG réduit les hallucinations, garantit la conformité réglementaire et offre des réponses précises. Voici comment maîtriser cette technologie.
Qu’est-ce que le Retrieval-Augmented Generation ?
Le RAG est un framework hybride qui intègre un mécanisme de recherche (base de données vectorielle, moteur sémantique) à un modèle génératif (comme GPT-5 ou Gemini). Contrairement aux LLMs classiques, il ne se base pas uniquement sur des connaissances pré-entraînées, mais enrichit ses réponses avec des données externes récupérées en temps réel (Squirro, 2025).
Architecture de référence
Un système RAG moderne se compose de :
-> Base de connaissances : documents internes (pdf, csv, etc.), bases de données structurées, APIs métier.
-> Embedder : le modèle de plongement lexical (exemple : OpenAI Embeddings) est utilisé pour transformer les données en représentations vectorielles. Les embeddings ainsi créés capturent les relations sémantiques entre les mots, améliorant la précision des recherches et des analyses contextuelles.
-> Vector Stores : des bases de données conçues pour gérer des données sous forme de vecteurs, facilitant ainsi une recherche sémantique avancée. Ces systèmes, comme Chroma et Milvus, sont spécialement optimisés pour interpréter les relations et les similarités entre des ensembles de données vectorielles. Elles assurent que les informations les plus pertinentes et contextuelles sont accessibles pour enrichir les réponses générées par les modèles d'IA.
-> LLM : modèle génératif contextualisé par les résultats de recherche.
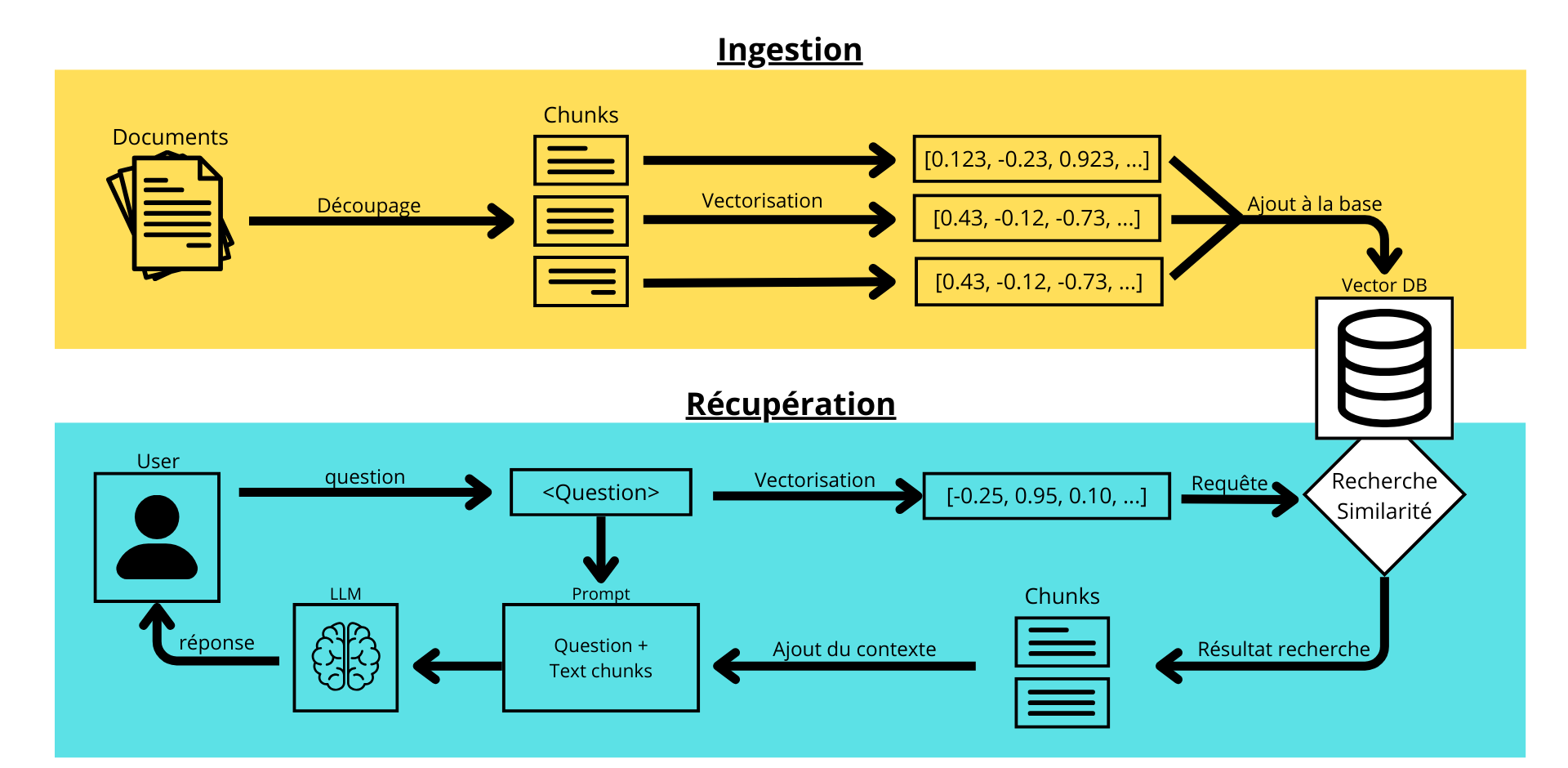
Pour mieux comprendre le fonctionnement du RAG, voici une explication étape par étape illustrant le parcours de la donnée, de son ingestion jusqu’à la génération d’une réponse enrichie pour l’utilisateur :
Phase d'ingestion
La première étape consiste à préparer la base de connaissances :
Documents sources : Le processus commence avec des documents bruts (PDF, texte, pages web, etc.)
Découpage en chunks : Les documents sont segmentés en fragments de taille optimale, généralement 200-500 tokens pour maintenir la cohérence sémantique
Vectorisation : Chaque chunk est transformé en vecteur numérique via un modèle d'embedding.
Stockage : Les vecteurs sont indexés dans une base de données vectorielle (Vector DB) pour permettre la recherche de similarité
Phase de récupération
Lors d'une requête utilisateur, le système active le processus de génération augmentée :
Question utilisateur : L'utilisateur pose sa question au système
Vectorisation de la requête : La question est convertie en vecteur dans le même espace sémantique que les documents.
Recherche par similarité : Le système interroge la base vectorielle pour trouver les chunks les plus pertinents
Enrichissement du prompt : Les chunks récupérés sont ajoutés comme contexte à la question originale
Génération LLM : Le modèle de langage produit une réponse en s'appuyant sur le contexte fourni et la question
Réponse finale : L'utilisateur reçoit une réponse factuelle et contextualisée
Cette architecture garantit que les réponses sont ancrées dans des sources fiables tout en bénéficiant des capacités de génération naturelle des LLMs
Cette architecture garantit que les réponses sont ancrées dans des sources fiables tout en bénéficiant des capacités de génération naturelle des LLMs.
Vous hésitez encore ou avez besoin d'un accompagnement spécifique, notre équipe est à votre écoute
Les nouvelles variantes de RAG
En 2025, plusieurs variantes innovantes du RAG ont émergé, chacune répondant à des besoins spécifiques et offrant des avantages distincts. Voici un aperçu de ces déclinaisons :
Self-RAG : Cette variante est conçue pour réduire les erreurs d'interprétation. Elle incorpore un système de vérification automatique permettant de corriger les hallucinations du modèle en évaluant la fiabilité des sources utilisées. Ainsi, elle garantit une précision accrue des informations fournies.
GraphRAG : Adaptée aux recherches impliquant des relations complexes, GraphRAG exploite des structures de données en graphes pour mieux contextualiser les informations. En analysant les interconnexions entre différents éléments, elle offre une compréhension plus profonde et raffinée du sujet traité.
Golden-Retriever : Cette variante met l'accent sur la gestion prioritaire des données essentielles. En renforçant la conformité aux normes RGPD, elle assure une meilleure protection des informations critiques, tout en optimisant leur utilisation pour produire des réponses pertinentes.
CAG : Le Cache-Augmented Generation (CAG) est une approche innovante qui vise à
optimiser la rapidité et la fiabilité des modèles de langage, en
particulier pour les tâches nécessitant beaucoup de connaissances.
Contrairement au RAG, qui effectue une recherche dynamique dans une
base de données externe à chaque requête, le CAG précharge l’ensemble du
corpus de connaissances pertinent directement dans la fenêtre de
contexte élargie du modèle avant toute interaction utilisateur.
SuperRAG 2.0 : Conçu pour les environnements multilingues et les entreprises manipulant de vastes volumes de données, SuperRAG 2.0 propose une scalabilité améliorée. Sa capacité à traiter efficacement les données de différentes langues le rend indispensable pour les organisations ayant des besoins diversifiés.
Chacune de ces variantes du RAG contribue à enrichir l'écosystème des systèmes d'IA générative en entreprise, en répondant à des préoccupations spécifiques tout en offrant des fonctionnalités avancées.
Choisir sa base de données vectorielle
Le choix d’une base de données vectorielle est une étape stratégique
dans la conception d’un système RAG performant. Il faut d’abord analyser
la nature de vos données (textes, images, multimodalité), le volume à
indexer, la fréquence des mises à jour, les exigences de latence, la
scalabilité attendue et les besoins d’intégration avec votre stack
technique. Les bases vectorielles dédiées, comme Pinecone, Milvus ou
Qdrant, offrent généralement des performances supérieures pour la
recherche de similarité à grande échelle, avec une gestion optimisée des
index et des fonctionnalités avancées (filtrage, gestion fine des
métadonnées, réplication).
Les solutions comme Chroma sont appréciées pour leur simplicité
d’intégration et leur compatibilité avec les frameworks LLM modernes,
tandis que Weaviate se distingue par ses capacités de gestion de graphes
de connaissances et ses plugins d’extension.
À côté de ces solutions spécialisées, on trouve des bases de données
généralistes (PostgreSQL, Elasticsearch, Redis) enrichies d’extensions
vectorielles, pertinentes pour les équipes souhaitant mutualiser leur
infrastructure existante (LeMondeInformatique, 2024).
En 2025, les principaux choix du marché incluent :
Milvus (open source, très performant sur gros volumes, adapté au temps réel)
Qdrant (open source, API flexible, très bon rapport performance/fonctionnalités)
Chroma (open source, idéal pour prototypage et intégration rapide avec LangChain et LlamaIndex)
Weaviate (open source, gestion native des schémas et métadonnées, extensible par plugins)
FAISS (librairie de Facebook, très
utilisée pour la recherche d’images et de similarité, mais nécessite une
orchestration supplémentaire pour la production)
LanceDB, Marqo, Vespa (solutions émergentes, chacune avec des atouts spécifiques selon les cas d’usage)
Le choix final doit se faire en fonction de vos cas
d’usage : Pinecone et Milvus conviennent aux applications nécessitant
une très forte scalabilité et une faible latence, Qdrant et Chroma sont
parfaits pour des déploiements rapides et flexibles, tandis que Weaviate
s’impose pour les besoins avancés de gestion de graphes de
connaissances et de métadonnées.
Conclusion
En explorant les différentes composantes et variantes du RAG, il est clair que cette approche offre des possibilités vastes et adaptées à des besoins variés. La capacité de combiner la puissance des modèles de langage génératif avec des données externes enrichit considérablement la qualité des réponses fournies. Chaque étape, de l'ingestion des données à la génération finale, est conçue pour maximiser l'efficacité et la pertinence, assurant ainsi une expérience utilisateur améliorée.
Choix stratégique des technologies
Le succès d'un pipeline RAG repose sur la sélection judicieuse de ses composants techniques, notamment la base de données vectorielle. Comme nous l'avons vu, plusieurs options s'offrent aux développeurs, chacune avec ses avantages et ses inconvénients. La clé est de choisir une solution qui s'aligne avec les besoins spécifiques de l'organisation en termes de volume de données, de latence, de scalabilité, et de facilité d'intégration.
Perspectives d'avenir
Avec l'évolution rapide des technologies liées au RAG, nous pouvons nous attendre à des améliorations continues en termes de précision et de capacités de traitement. Les nouvelles variantes, telles que Self-RAG et SuperRAG 2.0, montrent comment cette technologie peut être adaptée pour répondre aux défis spécifiques que rencontrent les entreprises modernes. La mise en œuvre de telles solutions nécessite une compréhension approfondie des besoins et une anticipation des évolutions technologiques futures.
Application pratique
Pour les entreprises, l'intégration d'un pipeline RAG peut transformer la manière dont elles accèdent et utilisent les informations. Que ce soit pour améliorer le service client, optimiser les processus internes, ou encore développer de nouveaux produits, les applications possibles sont vastes. Un pipeline bien conçu peut non seulement fournir des réponses plus précises et contextualisées, mais aussi permettre de nouvelles formes d'interaction avec les données.
En conclusion, l'implémentation d'un pipeline RAG robuste avec LlamaIndex et la sélection appropriée d'une base de données vectorielle sont essentielles pour tirer parti du potentiel de cette technologie. Une compréhension profonde des concepts et des choix technologiques permettra d'exploiter pleinement les capacités du RAG pour stimuler l'innovation et la compétitivité des entreprises dans un environnement numérique en constante évolution.
Envie de vous formez à l'IA générative ?
Partager avec
💙 Merci d'avoir parcouru l'article jusqu'à la fin !
Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.