Construisez des pipelines de données robustes, scalables et prêts pour la production. Devenez un ingénieur data capable de concevoir, déployer et industrialiser des architectures modernes cloud & Big Data.
TL;DR : ScrapeGraphAI et Diffbot incarnent deux visions opposées de l’extraction web pour LLM : l’un utilise des prompts pour générer des graphes d’actions ciblées, l’autre s’appuie sur une infrastructure propriétaire et des modèles de classification multi-types. Le premier brille par sa flexibilité et sa précision sur mesure ; le second par sa robustesse à grande échelle. Cet article vous aide à choisir selon vos besoins : extraction précise ou ingestion massive.
ScrapeGraphAI vs Diffbot : ce duel incarne deux visions radicalement différentes de l’extraction web pour les workflows RAG. D’un côté, ScrapeGraphAI vous permet de piloter l’extraction par prompt, en générant dynamiquement des graphes d’actions à partir de requêtes en langage naturel. De l’autre, Diffbot propose une API propriétaire complète, capable d’ingérer n’importe quelle URL et d’en extraire automatiquement des données structurées selon leur typologie (article, produit, entreprise…).
Cette opposition soulève une question clé pour les ingénieurs RAG et data scientists :
→ Faut-il privilégier la précision pilotée par IA ou la scalabilité plug-and-play ?
En effet, selon votre cas d’usage – extraction ponctuelle de fiches produits, collecte automatique d’articles de presse ou création d’un graphe de connaissances – le bon choix d’outil peut considérablement optimiser vos performances, vos coûts et votre temps de développement.
ScrapeGraphAI : extraction intelligente pilotée par LLM
ScrapeGraphAI repose sur une idée forte : utiliser des grands modèles de langage (LLM) pour automatiser des tâches complexes de scraping via des graphes d’actions générés à partir de prompts. C’est un projet open-source sous licence MIT, très communautaire, qui a explosé en popularité en 2024 avec près de 20 000 étoiles GitHub (ScrapeGraphAI, 2024).
Une logique de graphe déclarative et flexible
Contrairement à un scraper classique où vous devez coder chaque étape d’extraction, ScrapeGraphAI vous laisse simplement décrire ce que vous voulez extraire (ex : “récupère le titre, le prix et la description sur cette page produit”), et le système se charge :
de comprendre la page avec un LLM (comme GPT-4),
de générer un graphe de scraping (actions DOM, clics, parsing, etc.),
d’exécuter ce graphe pour renvoyer les données extraites, souvent en JSON ou Markdown.
L’outil propose différents types de graphes comme SmartScraperGraph, MultiGraph (multi-pages), SearchGraph (scrape via recherche), ou ScriptCreatorGraph (génère du code Python autonome pour rejouer l’extraction).
Précision de l’extraction guidée par prompt
Grâce à son approche LLM-driven, ScrapeGraphAI excelle dans les cas où l’on cherche à extraire des données ciblées et précises. Il revendique une précision d’extraction jusqu’à 97,5 % sur des tâches complexes (ScrapeGraphAI, 2024). Contrairement à des extracteurs bruts, il comprend la structure sémantique de la page.
Cela le rend particulièrement utile pour :
Extraire des fiches produit de sites e-commerce variés (titre, prix, description…),
Collecter les statistiques spécifiques ou citations dans des articles presse,
Générer un tableau de résultats à partir de plusieurs pages.
Cas d’usage : fiches produits, veille automatisée, scraping multi-sites
ScrapeGraphAI est un choix pertinent si vous avez besoin de :
Scraping intelligent avec logique d’interaction (ex : cliquer, accepter les cookies, paginer),
Résultats propres et unifiés en JSON, Markdown ou résumé synthétique,
Génération de code (extraction reproductible),
Veille sur plusieurs sources (ex : top 10 résultats Google d’un terme, analysés automatiquement).
Il brille sur les tâches ponctuelles, exigeantes en précision, et multi-domaines – là où un extracteur générique peut perdre en pertinence.
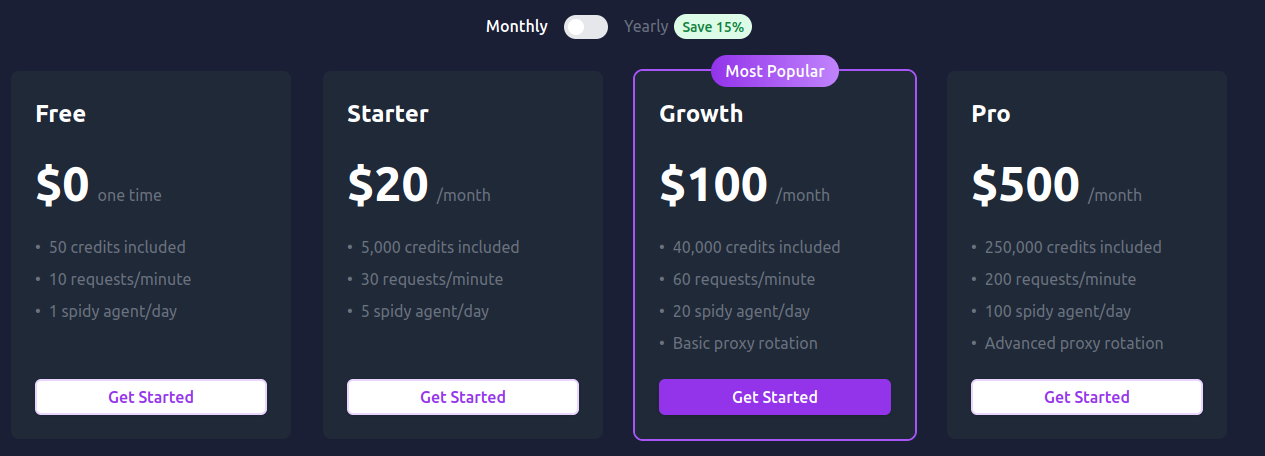
Tarification (SaaS)
Diffbot : API industrielle pour données LLM-ready
Diffbot adopte une toute autre approche : plutôt que de générer dynamiquement des instructions via des prompts, il s’appuie sur une API propriétaire “tout-en-un” fondée sur des modèles de classification automatique. Son objectif ? Transformer n’importe quelle page web en données structurées prêtes à l’emploi pour vos pipelines RAG ou bases de connaissances.
Modèle de classification automatique et typage sémantique
Au cœur de Diffbot, on trouve un modèle NLP multi-types propriétaire capable d’identifier et structurer automatiquement les pages selon leur nature :
Article de presse
Fiche produit
Profil d’entreprise
Page générique…
L’API renvoie un JSON typé, contenant des champs riches : auteur, date, contenu, prix, image, entreprise, etc. Sans prompt, sans réglage, vous obtenez un résultat immédiatement exploitable, notamment pour alimenter des bases vectorielles ou knowledge graphs.
Robustesse, scalabilité et simplicité d’intégration
Pensé pour les projets industriels, Diffbot offre une robustesse éprouvée :
Infrastructure cloud scalable (des millions de pages/jour)
Gestion automatique des erreurs, délais, sites JavaScript
Support de la pagination, liens internes, règles robots.txt
Vous pouvez l’appeler via une simple URL avec clé API (REST), ou intégrer ses SDK dans vos pipelines. Diffbot propose aussi des outils de “crawling enrichi”, capables d’explorer un site complet et de classifier chaque page automatiquement.
Cas d’usage : presse, annuaires, bases produits globales
Les cas d’utilisation de Diffbot s’alignent sur des besoins de couverture large et régulière :
Indexation massive de sites de presse (pour construire une base de données d’articles)
Surveillance concurrentielle sur des marketplaces (extraction de fiches produit à l’échelle)
Création de graphes d’entreprise à partir de pages publiques (type Crunchbase-like)
Son API permet de traiter en masse des milliers de pages, sans supervision humaine, ce qui en fait une solution de choix pour des entreprises en veille, e-commerce, ou recherche documentaire.
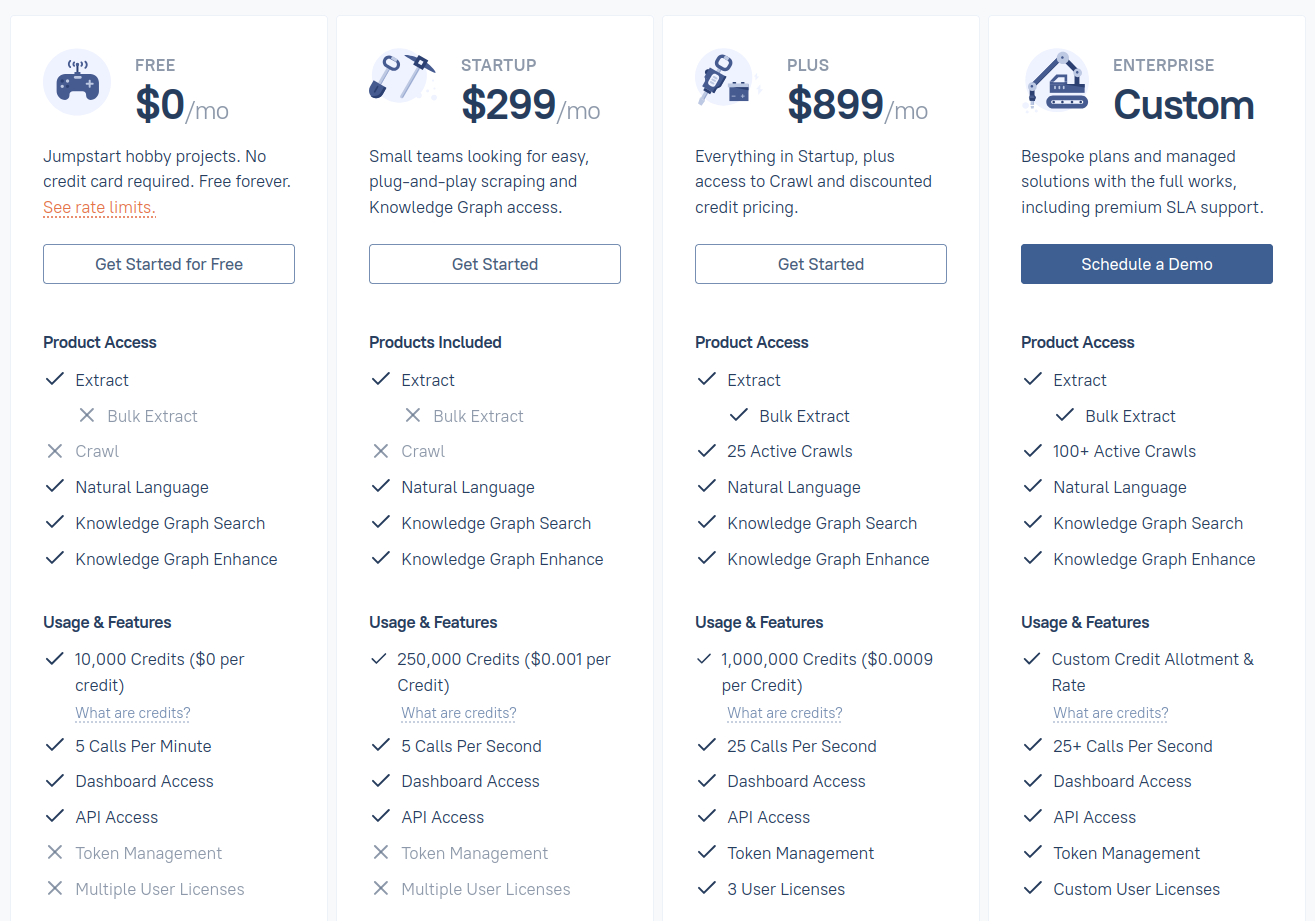
Tarification
Vous hésitez encore ou avez besoin d'un accompagnement spécifique, notre équipe est à votre écoute
Tableau comparatif : ScrapeGraphAI vs Diffbot
Ce tableau synthétise les principales différences entre ScrapeGraphAI et Diffbot, selon les critères les plus pertinents pour un projet RAG ou d’extraction web orientée IA.
Critère
ScrapeGraphAI
Diffbot
Type d’outil
Open-source (MIT), framework Python piloté par prompts
API SaaS propriétaire, full-stack
Approche
Extraction guidée par LLM et logique de graphe
Classification automatique multi-types
Entrée utilisateur
Prompt en langage naturel
URL (aucun réglage requis)
Qualité de l’extraction
Très précise et ciblée, format JSON/Markdown personnalisé
Payant (SaaS) ou Gratuit (en local - hors usage de LLM payants comme GPT-4)
Payant (par volume/API), coût à prévoir à grande échelle
Communauté & support
+20k étoiles GitHub, Discord actif
Support pro, API stable, documentation détaillée
Licence
MIT, usage libre y compris commercial
Propriétaire (licence SaaS)
Ce qu’il faut retenir
Choisissez ScrapeGraphAI si vous voulez contrôler finement l’extraction, notamment sur des sites variés ou pour générer des scripts de scraping dynamiques.
Préférez Diffbot si vous cherchez l’efficacité industrielle : ingestion massive, typage automatique et intégration sans friction dans une stack RAG.
Quand utiliser ScrapeGraphAI ? Quand préférer Diffbot ?
Le bon choix dépend de vos priorités : flexibilité et précision ou rapidité et volume. Voici un guide de décision clair selon les scénarios fréquents en extraction web pour LLM.
Vous souhaitez contrôler l’extraction finement, avec des prompts adaptables selon la structure du site.
Votre pipeline RAG implique une compréhension contextuelle des pages (via LLM).
Vous visez des cas d’usage ponctuels, sur quelques dizaines ou centaines de pages.
Vous voulez générer des scripts de scraping réutilisables sans les coder à la main.
🧠 Idéal pour un expert data qui veut maîtriser la logique d’extraction à la volée, avec un coût réduit.
✅ Préférez Diffbot si…
Vous devez ingérer des milliers de pages rapidement et sans supervision humaine.
Vous cherchez des données structurées typées automatiquement (articles, fiches produits…).
Vous construisez une base de connaissances web à grande échelle (veille, agrégation…).
Vous intégrez l’extraction dans une chaîne CI/CD et vous cherchez une API stable prête à l’emploi.
Vous privilégiez la robustesse, le support pro et la documentation exhaustive.
🏢 Parfait pour une entreprise ou une équipe R&D qui vise une industrialisation du crawl.
💡 À noter : Rien n’interdit de combiner les deux.
Par exemple, utilisez Diffbot pour collecter un grand volume de pages et ScrapeGraphAI pour en extraire ensuite les éléments les plus fins ou générer des résumés ciblés.
Conclusion : extraction pilotée ou ingestion full-stack ?
Le choix entre ScrapeGraphAI et Diffbot n’est pas qu’une affaire de performance technique : il reflète deux visions de l’extraction web pour les modèles de langage.
ScrapeGraphAI, c’est l’outil des développeurs explorateurs. Il vous donne les moyens de piloter chaque étape de l’extraction avec une précision chirurgicale, grâce à des prompts naturels et une orchestration fine via des graphes intelligents.
Diffbot, c’est le compagnon industriel. Une API robuste, optimisée pour avaler des millions de pages, comprendre leur structure automatiquement, et renvoyer des données prêtes à l’emploi pour vos LLM ou knowledge graphs.
👉 Vous travaillez sur un cas ponctuel, complexe, ou hautement personnalisable ? Misez sur ScrapeGraphAI.
👉 Vous construisez une base de données massive, uniforme, évolutive ? Appuyez-vous sur Diffbot.
Dans les deux cas, vous alimentez des workflows RAG plus puissants, plus rapides, et surtout mieux alignés sur vos besoins réels.
Envie de vous former à l'IA générative
Partager avec
💙 Merci d'avoir parcouru l'article jusqu'à la fin !
Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.