
Artificial Intelligence
Python
Cloud
Web Development
JavaScript
Crawl4AI vs Spider : framework Python ou API ultra-scalable ?

Lead Developer, Expert Cloud et DevOps
Publié le 4 juin 2025 · 10 min de lecture
Table de matières
Partager avec
Dans un workflow RAG (Retrieval-Augmented Generation), l’extraction de contenu web en temps réel ou en amont est un maillon stratégique. Deux approches dominent aujourd’hui : les frameworks Python à auto-héberger comme Crawl4AI, et les API SaaS plug-and-play comme Spider. Ce duel oppose donc deux visions : maîtrise technique complète d’un côté, simplicité scalable de l’autre.
Le présent comparatif “Crawl4AI vs Spider” vous aide à choisir selon vos contraintes : time-to-prod, budget, scalabilité, ou encore conformité à robots.txt et RGPD. Vous êtes une startup en quête d’efficacité ? Ou un laboratoire IA qui préfère le contrôle ? Ce guide vous éclaire point par point.
TL;DR : Crawl4AI offre un contrôle total et une personnalisation
fine pour les développeurs Python, tandis que Spider séduit par sa
simplicité, sa vitesse cloud-native et son API prête à l’emploi. Pour un
projet RAG rapide à mettre en production, Spider domine. Pour un
pipeline sur-mesure et auto-hébergé, Crawl4AI est le choix idéal.
Spider : une API clé-en-main pensée pour l’industrialisation
API ultra-rapide, cache LLM, gestion des proxies intégrée
Spider est un service SaaS qui propose une API REST prête à l’emploi pour crawler et scraper le web sans rien héberger. Une simple requête
POST, et vous recevez un Markdown LLM-ready, du HTML propre ou du texte brut — le tout nettoyé, structuré et sans boilerplate.L’API supporte les pages JavaScript, les CAPTCHA, la pagination automatique, les clics intelligents via IA, et repose sur une architecture cloud scalable. Elle intègre un cache d’interactions IA, utile pour éviter de réexécuter les mêmes actions sur des pages similaires.
Qualité Markdown LLM-ready et orchestration cloud
Spider excelle dans la restitution du contenu : chaque page est analysée, nettoyée, transformée, et enrichie de métadonnées (titre, URL, images, liens internes). Grâce à l’intégration officielle dans LangChain (
SpiderLoader), il s’insère directement dans un pipeline RAG, en mode scrape ou crawl. Des webhooks et un tableau de bord facilitent le suivi des crawls à grande échelle.Tarifs clairs, time-to-prod minimal
Spider propose un free tier et des plans payants à partir de quelques dizaines d’euros par mois. Le pricing dépend du volume de pages et de la rapidité (nombre de threads). Contrairement à une stack auto-hébergée, le time-to-production est quasi-instantané : pas de serveur, pas de proxy à gérer, pas de scraping à coder.
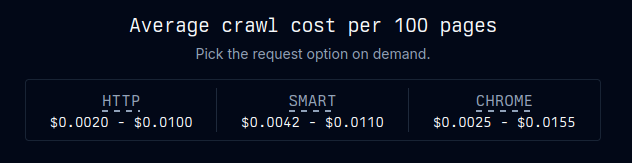
Conformité par défaut, monitoring avancé
Côté éthique, Spider respecte nativement les directives robots.txt, introduit des délais anti-surcharge, et affiche l’origine des données (titres, URLs). Le traitement des pages s’effectue côté serveur Spider, sans stockage persistant — utile pour rester conforme RGPD. Un tableau de bord permet de superviser taux d’échec, erreurs, et réessais automatiques.
Partager avec
💙 Merci d'avoir parcouru l'article jusqu'à la fin !

Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.
» En savoir plusArticles associés
Voir tous nos articles →
janvier 23, 2025
Cache-Augmented Generation (CAG) : La nouvelle évolution du RAGTemps de lecture : 10 min

janvier 27, 2025
Guide LangChain : révolutionnez vos applications en y intégrant l'IA générativeTemps de lecture : 4 min


juin 3, 2025
Comment choisir les meilleurs outils d’exploration web RAG (2025)Temps de lecture : 10 min
Formations associés
Toutes nos formations →
Préparez la certification Azure AI‑102
20 heures
Débutant
Garantie

Préparez la certification PL‑300
24 heures
Débutant
Garantie

Préparez la certification AZ-900
10 heures
Débutant
Garantie

Préparez la certification DP‑700
24 heures
Débutant
Garantie

Préparez la certification DP‑900
10 heures
Débutant
Garantie
