
Artificial Intelligence
LLM
Cache-Augmented Generation (CAG) : La nouvelle évolution du RAG

Lead Developer, Expert Cloud et DevOps
Publié le 23 janvier 2025 · 10 min de lecture
Table de matières
Partager avec
La génération augmentée par récupération (RAG) révolutionne l'IA moderne en permettant aux modèles de langage avancés (LLM) d'intégrer des connaissances externes pour des réponses plus pertinentes et précises. Cependant, son processus traditionnel, basé sur une récupération en temps réel, peut entraîner des délais et une certaine complexité. Pour y remédier, la génération augmentée par cache (CAG) propose une approche innovante : intégrer directement les connaissances nécessaires dans le contexte du modèle, éliminant ainsi la phase de récupération en temps réel. Cet article explore et compare ces deux approches, en analysant leurs avantages, leurs limites et leurs usages possibles.
Rappel : La génération augmentée par récupération - RAG (Retrieval-Augmented Generation)
Le RAG repose sur une étape de récupération en temps réel pour intégrer des connaissances externes aux réponses des LLM. À chaque requête utilisateur, le système recherche des documents pertinents dans une base de connaissances et les intègre au prompt avant de générer une réponse.
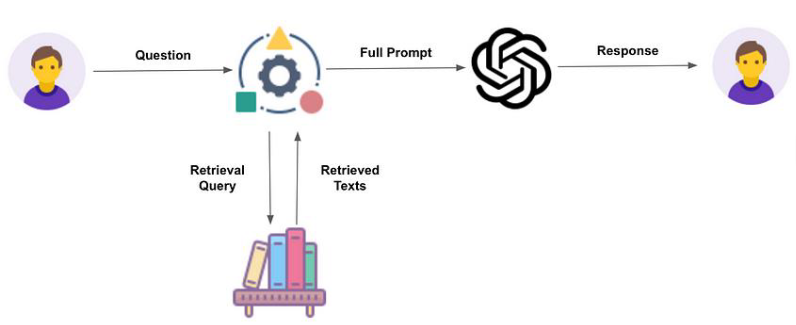
Avantages :
- Données Actualisées : Permet d’accéder à des informations récentes et dynamiques.
- Légèreté du Modèle : Le stockage des connaissances dans une source externe allège le modèle.
- Réduction des Hallucinations : Les réponses sont basées sur des documents réels.
Inconvénients :
- Latence : La récupération en temps réel peut ralentir les réponses.
- Complexité Systémique : Maintenir une base de données actualisée est coûteux.
- Erreurs de Récupération : Des documents non pertinents peuvent être sélectionnés.
Exemple :
Un service client virtuel pour une boutique en ligne utiliserait le RAG pour fournir des réponses précises aux questions des clients concernant les stocks actuels ou les délais de livraison.
Par exemple, un utilisateur demandant : « Cet article est-il encore disponible en taille M et combien de temps prendra la livraison ? » verrait le système :
- Analyser la requête.
- Récupérer les documents pertinents dans la base de connaissances en temps réel.
- Générer une réponse basée sur les informations récupérées.
Une Approche Innovante : La génération augmentée par cache - CAG (Cache-Augmented Generation)
Le CAG réinvente le paradigme en préchargeant les informations pertinentes dans le contexte étendu des LLM, éliminant le besoin de récupération dynamique.
Fonctionnement :
- Prétraitement : Les connaissances nécessaires sont identifiées et organisées avant l’utilisation.
- Mise en Cache : Les données prétraitées sont intégrées directement dans la mémoire du modèle lors de son initialisation.
- Utilisation : Lorsque l’utilisateur pose une question, le modèle accède à ces données déjà préchargées pour fournir une réponse rapide et précise.
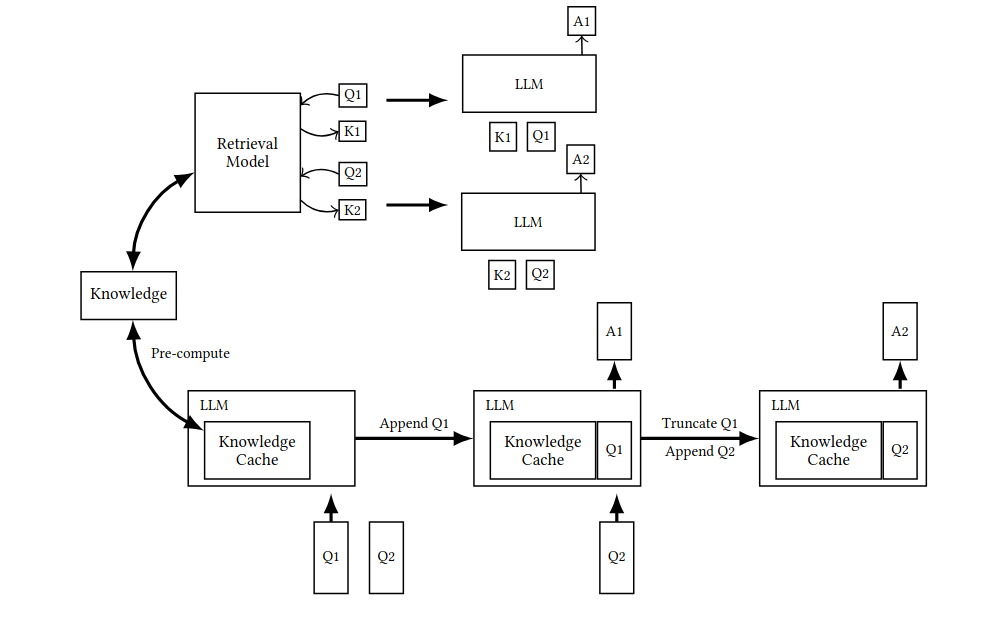
Schéma de l'article : « Don’t Do RAG : When Cache-Augmented Generation is All You Need for Knowledge Tasks » (Chan et al., 2024)
Le schéma ci-dessus illustre la comparaison des flux de travail traditionnels RAG et de la méthode CAG : La section supérieure illustre le pipeline RAG, incluant la récupération en temps réel et l'entrée de texte de référence pendant l'inférence, tandis que la section inférieure présente notre approche CAG, qui précharge le KV-cache, éliminant ainsi l'étape de récupération et l'entrée de texte de référence lors de l'inférence.
Avantages :
- Temps de Réponse Accéléré : Absence de délai lié à la récupération.
- Simplicité Architecturale : Réduction de la complexité opérationnelle.
- Cohérence des Réponses : Utilisation d’un contexte fixe pour des réponses uniformes.
- Efficacité : Moindre charge de calcul grâce à l’évitement des étapes redondantes de récupération.
Limites :
- Fenêtre de Contexte Limitée : Impossible de précharger de grandes bases de connaissances.
- Données Statiques : Peu adapté aux environnements dynamiques.
- Coûts Initiaux : Les ressources nécessaires pour la préparation des caches sont élevées.
Exemple :
Une plateforme d’apprentissage pourrait précharger des modules d’enseignement pour des cours spécifiques.
Si un étudiant demande : « Quels sont les concepts clés du calcul différentiel ? », le système :
- Accède aux ressources éducatives préchargées.
- Propose une explication structurée et immédiate, incluant des exemples pratiques.
Partager avec
💙 Merci d'avoir parcouru l'article jusqu'à la fin !

Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.
» En savoir plusArticles associés
Voir tous nos articles →
janvier 2, 2025
Divisez votre dataset avec train_test_split de scikit learn - Tutoriel pratique en PythonTemps de lecture : 12 min

avril 16, 2025
Le guide ultime pour surveiller vos applications IA avec LangSmithTemps de lecture : 10 min




juin 4, 2025
Firecrawl vs Diffbot : extraction web nouvelle génération ou robustesse éprouvée ?Temps de lecture : 10 min

Formations associés
Toutes nos formations →
Préparez la certification Azure AI‑102
20 heures
Débutant
Garantie

Préparez la certification PL‑300
24 heures
Débutant
Garantie

Préparez la certification AZ-900
10 heures
Débutant
Garantie

Préparez la certification DP‑700
24 heures
Débutant
Garantie

Préparez la certification DP‑900
10 heures
Débutant
Garantie
