Construisez des pipelines de données robustes, scalables et prêts pour la production. Devenez un ingénieur data capable de concevoir, déployer et industrialiser des architectures modernes cloud & Big Data.
TL;DR : Firecrawl séduit par sa rapidité, son format Markdown et son coût abordable pour des projets RAG modernes. Diffbot, avec ses API Article et Product, mise sur la fiabilité, le NLP profond et une extraction via vision par ordinateur éprouvée. Firecrawl est idéal pour les développeurs LLM, Diffbot pour les équipes data à la recherche de robustesse et d’analytique structurée.
Pourquoi comparer Firecrawl et Diffbot ?
Deux philosophies d'extraction web pour l'IA
Firecrawl vs Diffbot : le match oppose deux générations d’outils d’extraction web au service de l’IA générative. D’un côté, Firecrawl, un framework moderne pensé pour les workflows LLM-ready, qui transforme des pages web en Markdown propre à la volée. De l’autre, Diffbot, une API d’extraction structurée basée sur la vision par ordinateur, présente depuis plus d’une décennie, et utilisée par des entreprises du Fortune 500 pour bâtir des bases de données web enrichies.
Si vous construisez un moteur RAG (Retrieval-Augmented Generation), un assistant intelligent ou une base documentaire automatisée, le choix de la technologie d’ingestion est stratégique : rapide et minimaliste, ou structuré et analytique ? Firecrawl et Diffbot incarnent deux réponses opposées à cette question.
LLM-ready ou NLP-first : un choix stratégique
Firecrawl privilégie la vitesse d’exécution, l’accessibilité (open-source, freemium SaaS) et l’intégration directe dans des pipelines IA comme LangChain, LlamaIndex ou Flowise. Il génère un contenu prêt à être utilisé immédiatement dans un modèle de langage.
Diffbot, quant à lui, mise sur la profondeur : il analyse la page via un moteur de computer vision + NLP pour restituer un JSON sémantique. Son Article API isole titres, auteurs, contenu, images, et sa Product API extrait automatiquement les spécifications d’un produit (prix, disponibilité, etc.) – idéal pour des besoins de structuration poussée et d’analyse à grande échelle.
Chacun a sa place dans l’écosystème IA : encore faut-il choisir en connaissance de cause.
Firecrawl : la performance Markdown pensée pour le RAG
Un outil agile pour les workflows LLM modernes
Firecrawl a été conçu pour répondre aux nouveaux besoins de l’IA générative : fournir rapidement du contenu web propre, en Markdown ou JSON, parfaitement adapté aux modèles de langage. Ce crawler peut s’utiliser en mode SaaS via une API ou en self-hosted (licence AGPL), ce qui en fait un choix flexible pour les développeurs souhaitant garder la main sur leur infrastructure.
Il supporte les sites complexes (JavaScript dynamique, scroll infini, interactions utilisateur), grâce à l'intégration de Playwright en backend. Il filtre automatiquement les menus, publicités et autres éléments superflus pour ne conserver que le contenu utile aux LLM. Résultat : un texte clair, balisé, chunké, prêt pour l’indexation vectorielle ou la génération.
Firecrawl propose un découpage par sections, taille fixe ou regex, facilitant l’intégration dans des bases de vecteurs.
Extraction rapide, économique et auto-hébergeable
L’un des grands atouts de Firecrawl est sa vitesse d’exécution. Là où certains outils passent par un LLM pour interpréter une page, Firecrawl reste “blazing fast” grâce à une extraction DOM classique optimisée. Il est capable de crawler des milliers de pages par minute, avec un support natif du multi-threading, de la rotation de proxies, et de mécanismes anti-blocking (headers aléatoires, délais simulés…).
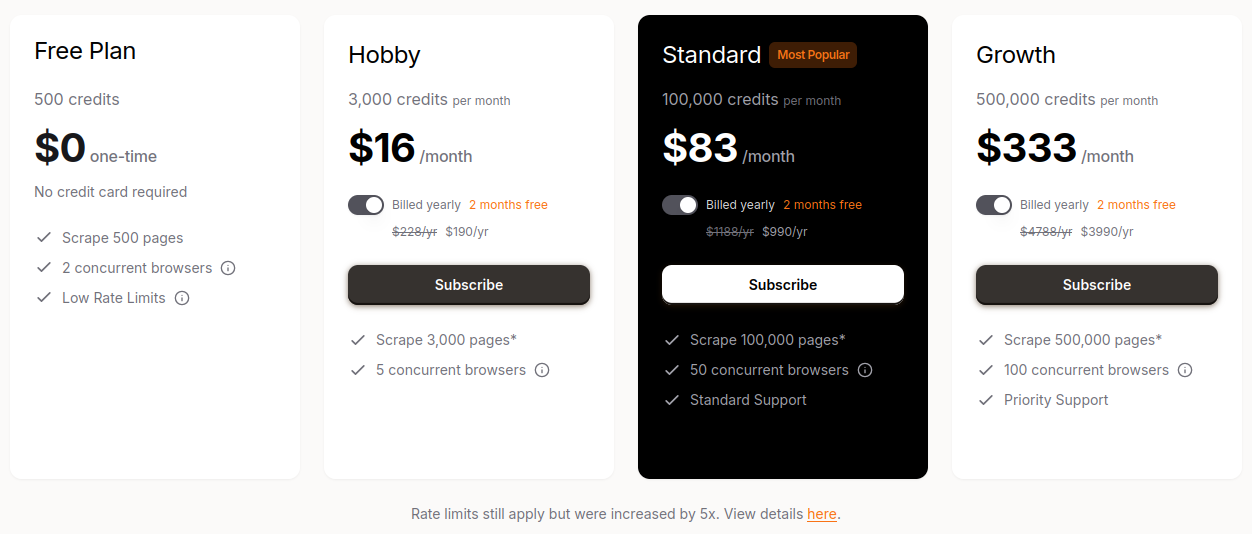
Côté coût, Firecrawl propose un plan freemium généreux (500 crédits gratuits/mois), puis des tarifs modulés selon volume, très compétitifs par rapport aux solutions historiques.
Firecrawl annonce une vitesse jusqu’à 4x supérieure à des scrapers IA pilotés par LLM.
Intégrations natives avec LangChain, LlamaIndex & co.
Firecrawl s’intègre parfaitement à l’écosystème IA-first. Il fournit des loaders officiels pour LangChain (JS et Python), LlamaIndex, Dify, Langflow, ou encore FlowiseAI. Que vous montiez un chatbot de documentation, un moteur de recherche sémantique ou un pipeline RAG complet, Firecrawl s’insère naturellement dans vos chaînes.
Il permet même une ingestion directe en Markdown dans un agent conversationnel, avec reprise sur erreur, planification de crawls, ou injection conditionnelle via Zapier ou Make.
Le connecteur FireCrawlLoader pour LangChain permet une ingestion directe avec un prompt LLM.
Tarification
Diffbot : vision par ordinateur au service des données structurées
Un vétéran de l’extraction web sémantique
Fondé en 2009, Diffbot fait figure de pionnier dans l’extraction de données structurées à partir de pages web. Sa technologie repose sur une combinaison unique de vision par ordinateur, NLP avancé et apprentissage automatique. Contrairement aux crawlers traditionnels qui parsèrent du HTML, Diffbot analyse visuellement la page comme le ferait un humain, détecte les zones d'intérêt (titres, images, tableaux) et restitue une sortie hautement structurée.
Son Knowledge Graph interne, composé de milliards d’entités, lui permet de croiser, enrichir et relier les données extraites à des entités du monde réel (personnes, entreprises, produits…).
Diffbot alimente des applications critiques en veille concurrentielle, en e-commerce ou en search intelligence depuis plus de 10 ans.
API Article & Product : profondeur NLP et structure analytique
Diffbot propose une suite d’API prêtes à l’emploi, dont deux se distinguent particulièrement :
Article API : isole automatiquement le titre, l’auteur, la date, le corps du texte, les images principales, les vidéos, les tags… Très utile pour extraire de l’information journalistique ou blog.
Product API : reconnaît automatiquement les fiches produit (e-commerce) et en extrait les spécifications (prix, disponibilités, variantes, etc.), même sur des sites complexes.
Les résultats sont fournis en JSON structuré, facilement intégrable dans un pipeline de données ou un moteur de recherche intelligent. La qualité de l’extraction est très stable, quel que soit le site cible.
Grâce à sa technologie visuelle, Diffbot peut extraire proprement des structures complexes inaccessibles aux parsers DOM classiques.
Scalabilité, enrichissement, et crawling corporate
Diffbot s’adresse clairement à une clientèle entreprise : son moteur de crawling est capable d’ingérer des millions de pages par jour, avec des mécanismes avancés de queueing, scheduling, et supervision. Il est utilisé par de grandes sociétés pour constituer des bases internes de données produits, médias ou B2B.
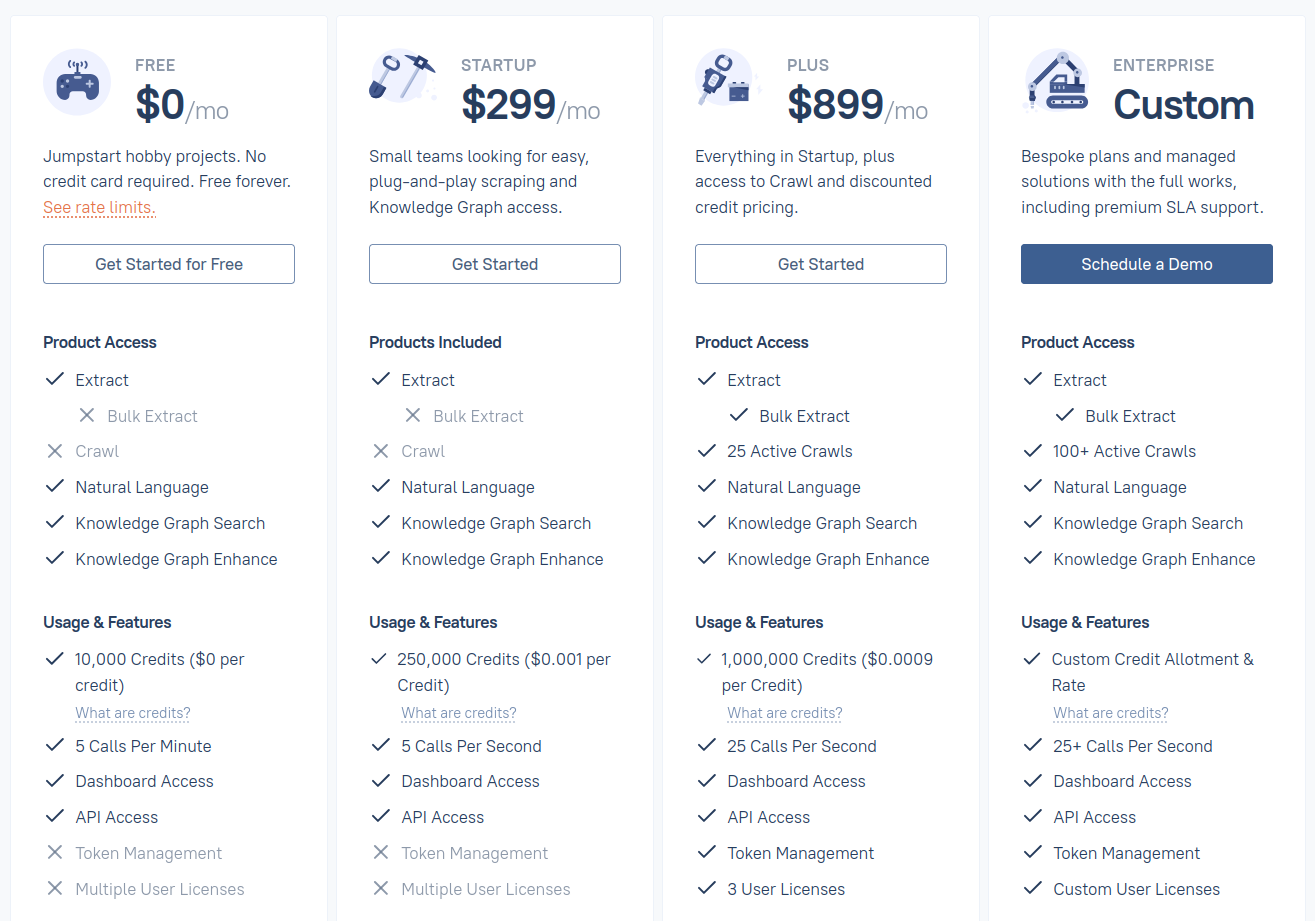
En plus des APIs publiques, Diffbot propose une Data-as-a-Service où vous spécifiez vos besoins et recevez les données extraites par ses robots, enrichies par son Knowledge Graph propriétaire. Il s’agit donc d’une solution clé en main avec peu de configuration, mais à un coût non négligeable.
Le Knowledge Graph de Diffbot recense plus de 10 milliards d’entités et 1 trillion de faits.
Tarification
Envie de vous former à l'IA générative ?
Comparatif Firecrawl vs Diffbot : que choisir selon votre besoin ?
Tableau synthétique des forces et faiblesses
Critère
Firecrawl 🟢 Moderne & léger
Diffbot 🟡 Robuste & structuré
Type
Open-source + SaaS
SaaS uniquement
Format de sortie
Markdown, JSON, HTML
JSON structuré enrichi
Technologie
Parsing DOM + Playwright
Vision + NLP + ML propriétaire
Vitesse
⚡ Très rapide, batch massif
🐢 Moins rapide mais plus précis
Compatibilité LLM
Directe (LangChain, LlamaIndex, etc.)
Indirecte (préparation de données)
Tarification
Freemium, scalable à bas coût
Abonnement entreprise (sur devis)
Cas d’usage idéal
Chatbot LLM, RAG, crawl Markdown
Scraping analytique, data B2B/e-commerce
Personnalisation
Forte (auto-hébergement possible)
Limitée (API packagée)
Complexité d’intégration
Faible (code Python/JS simple)
Moyenne (API à interroger, pas open-source)
Respect RGPD / robots.txt
Oui (personnalisable)
Oui (contrôle par Diffbot)
Cas d’usage typiques : RAG, veille, scraping produit
Cas d’usage
Outil recommandé
Pourquoi ?
Ingestion Markdown pour RAG
✅ Firecrawl
Sortie prête à l’emploi, chunking natif, intégration LangChain
Extraction produit (prix, specs, photos)
✅ Diffbot
API Product performante, structure clé/valeur fiable
Conclusion : innovation ou fiabilité ? Vous avez le choix.
Le duel Firecrawl vs Diffbot illustre parfaitement le dilemme entre modernité agile et fiabilité éprouvée.
Si vous êtes un développeur IA ou un ingénieur RAG, Firecrawl répond à vos besoins : rapide, LLM-ready, open-source, et facilement intégrable à vos chaînes LangChain ou LlamaIndex. Son export Markdown propre et son support des sites JavaScript en font un allié de choix pour l’ingestion web à grande échelle, sans friction ni coûts cachés.
En revanche, si votre priorité est la structuration sémantique, l’enrichissement via un Knowledge Graph, et une robustesse entreprise, Diffbot reste une référence. Ses API Article et Product offrent un niveau d’analyse avancé, particulièrement utile pour les projets analytiques, le commerce en ligne, ou les bases de données métier.
👉 Notre recommandation :
Choisissez Firecrawl si vous construisez un chatbot, un RAG ou un prototype IA avec ingestion web.
Préférez Diffbot si vous cherchez une extraction structurée fiable, destinée à être analysée, stockée ou monétisée.
Vous hésitez encore ou avez besoin d'un accompagnement spécifique, notre équipe est à votre écoute
Partager avec
💙 Merci d'avoir parcouru l'article jusqu'à la fin !
Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.