Construisez des pipelines de données robustes, scalables et prêts pour la production. Devenez un ingénieur data capable de concevoir, déployer et industrialiser des architectures modernes cloud & Big Data.
Saviez-vous que plus de 60 % des entreprises considèrent la sécurité des données comme le principal obstacle à l'adoption de l'IA générative ? Vos données internes sont un trésor : propriété intellectuelle, informations financières, données RH... Les exposer à des services d'IA tiers, c'est ouvrir la porte à des risques inacceptables. Pourtant, l'envie d'exploiter la puissance des grands modèles de langage (LLM) pour améliorer la productivité est bien réelle. La solution ? Un chatbot interne, hébergé et maîtrisé de bout en bout, sur votre propre infrastructure. Cet article vous guide à travers les étapes clés pour bâtir une telle solution, sans compromis sur la sécurité.
Architecture de référence : l'isolation totale comme maître-mot
L'objectif est clair : aucune donnée sensible ne doit quitter votre périmètre de confiance.
L'architecture de notre chatbot interne repose donc sur un principe fondamental : l'exécution entièrement locale. Imaginez une forteresse numérique :
Réseau Isolé : Le système opère sur un segment réseau dédié, sans aucun accès direct à Internet. Toutes les communications entrantes et sortantes sont rigoureusement contrôlées.
Composants On-Premise : De la base de données vectorielle au LLM lui-même, chaque brique logicielle est installée et gérée sur vos serveurs. Aucune dépendance SaaS n'est tolérée.
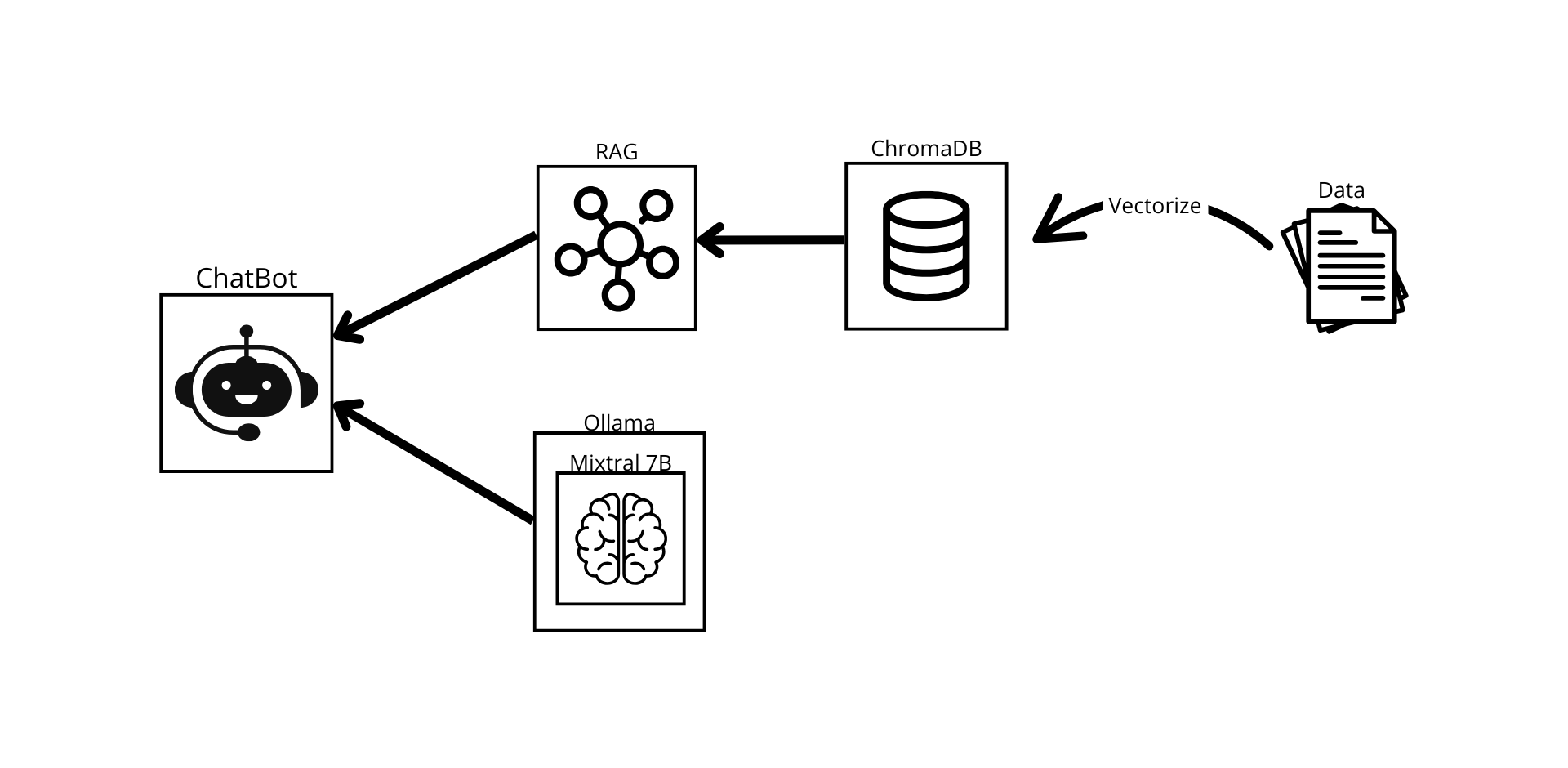
Flux de Données Maîtrisé : L'utilisateur interagit avec une interface web interne, qui communique avec le LLM et le système RAG (Retrieval-Augmented Generation) via des API sécurisées, le tout restant confiné à votre infrastructure.
Cette approche garantit une souveraineté totale sur vos données et les modèles qui les traitent.
Retrieval-Augmented Generation (RAG local) : la connaissance contextualisée et sécurisée
Un LLM, même puissant, ne connaît que ce sur quoi il a été entraîné. Pour lui donner accès à vos données internes de manière pertinente et sécurisée, nous utilisons le RAG. Ce mécanisme permet au LLM de "puiser" des informations dans une base de connaissance spécifique avant de générer une réponse.
Au cœur du RAG se trouve la base de données vectorielle. Elle stocke vos documents sous forme d'« embeddings » – des représentations numériques (vecteurs) de leur contenu sémantique.
Choix de la solution : Des options open-source robustes comme Chroma DB ou Qdrant peuvent être déployées localement. Elles offrent des fonctionnalités de recherche de similarité performantes, essentielles pour le RAG. Par exemple, Qdrant, écrit en Rust, est reconnu pour sa performance et son efficacité mémoire.
Préparation des données : Les documents (PDF, Word, intranets) sont découpés en segments, transformés en vecteurs par un modèle d'embedding (lui aussi local !), puis stockés.
Chiffrement des vecteurs & index
La sécurité des données au repos est primordiale.
Chiffrement intégral du disque : Le serveur hébergeant la base vectorielle doit utiliser le chiffrement intégral du disque (ex: LUKS pour Linux, BitLocker pour Windows Server).
Chiffrement au niveau de la base : Certaines bases vectorielles proposent des mécanismes de chiffrement des données au repos. Explorez ces options.
Chiffrement applicatif (optionnel) : Pour une sécurité maximale, les données brutes peuvent être chiffrées avant même leur vectorisation, avec une gestion rigoureuse des clés. Les vecteurs eux-mêmes, bien que moins directement intelligibles, doivent aussi être protégés, car ils représentent indirectement l'information.
LLM local / on-prem : le cerveau de l'opération
Le choix du LLM et de son moteur de déploiement est crucial. L'objectif est d'avoir un modèle performant fonctionnant exclusivement sur vos serveurs.
Moteurs de déploiement
Des outils facilitent grandement le déploiement et l'inférence de LLMs on-premise (notamment DeepSeek) :
Ollama : Simplifie le téléchargement et l'exécution de LLMs open-source (comme Llama 3, Mistral, etc.) sur des serveurs Linux ou macOS, y compris avec accélération GPU. Sa facilité d'utilisation en fait un excellent point de départ.
vLLM : Une bibliothèque optimisée pour un serving à haut débit des LLMs, particulièrement efficace pour maximiser l'utilisation des GPUs grâce à des techniques comme PagedAttention.
Critères de choix du modèle
Sélectionner le bon LLM pour un usage interne demande de considérer plusieurs facteurs :
Licence : Privilégiez des modèles avec des licences permissives pour un usage commercial interne (ex: Apache 2.0, MIT). Des modèles comme Llama 3 ont des licences spécifiques à examiner attentivement.
Taille du modèle : Exprimée en milliards de paramètres (ex: 7B, 13B, 70B). Un modèle plus grand est souvent plus performant mais requiert plus de ressources (VRAM GPU, RAM). Les modèles de 7B à 13B offrent un bon compromis pour des déploiements internes.
Performance GPU/CPU : Évaluez la VRAM nécessaire. Les modèles les plus importants nécessitent des GPUs haut de gamme (NVIDIA A100, H100). Des modèles plus petits ou quantizés peuvent tourner sur des GPUs plus modestes voire sur CPU pour des tests.
Quantization : Technique qui réduit la taille du modèle et accélère l'inférence en diminuant la précision des poids du modèle (ex: passage de 16 bits à 8 bits ou 4 bits avec des formats comme GGUF ou via des techniques comme AWQ/GPTQ). Cela permet de faire tourner des modèles plus grands sur des configurations matérielles plus modestes, avec une perte de performance souvent acceptable.
Voici un exemple d'architecture que nous pourrions avoir :
Gouvernance des données : qui voit quoi, et comment ?
Déployer un chatbot interne avec accès à des données sensibles impose une gouvernance stricte.
Filtrage & étiquetage des embeddings pour restreindre l’accès
Le RAG offre une opportunité unique de contrôle d'accès granulaire.
Métadonnées et tags : Lors de l'indexation de vos documents dans la base vectorielle, associez des métadonnées (tags) à chaque vecteur (ou groupe de vecteurs). Par exemple : département:RH, sensibilité:confidentiel, projet:Alpha.
Filtrage à la requête : Au moment de la recherche dans la base vectorielle, le système RAG doit filtrer les résultats en fonction des habilitations de l'utilisateur. Un utilisateur du département RH ne verra que les documents tagués département:RH.
Journalisation, versioning, politiques RGPD
La traçabilité et la conformité sont non négociables.
Journalisation exhaustive : Enregistrez toutes les requêtes, les réponses fournies, les documents sources utilisés par le RAG, et les accès aux données. Ces logs sont cruciaux pour les audits et la détection d'anomalies.
Versioning des données et modèles : Maintenez un historique des versions des documents ingérés et des modèles LLM utilisés pour assurer la reproductibilité et faciliter les retours en arrière.
Conformité RGPD : Assurez-vous que votre système respecte les principes du RGPD (droit à l'oubli, minimisation des données, etc.). La capacité de supprimer sélectivement des informations de la base vectorielle est essentielle.
Vous hésitez encore ou avez besoin d'un accompagnement spécifique, notre équipe est à votre écoute
Déploiement pas-à-pas : de l'idée à la production sécurisée
Un déploiement réussi suit une approche progressive.
Preuve de Concept (PoC) :
Sélectionnez un cas d'usage limité et un corpus de données restreint.
Déployez une version basique avec Ollama et un LLM de taille modeste (ex: Mistral 7B) sur un serveur de test.
Validez la pertinence des réponses et l'intégration RAG de base.
Durcissement Sécurité & Intégration RBAC :
Mettez en place le chiffrement de la base vectorielle et des communications.
Intégrez votre système d'authentification existant (LDAP, Active Directory, SSO) pour gérer les utilisateurs et les groupes.
Implémentez le filtrage des embeddings basé sur les groupes d'utilisateurs. Un utilisateur du groupe "ITSupport" ne verra que les documents techniques IT, tandis qu'un membre du groupe "HRManagers" accédera aux politiques RH.
Configurez la journalisation détaillée.
Mise en Production :
Déployez sur une infrastructure de production dimensionnée (CPUs, GPUs, RAM, stockage).
Mettez en place une supervision continue (monitoring des performances, des logs, des alertes de sécurité).
Prévoyez des sauvegardes régulières de la base vectorielle et des configurations.
Limites & bonnes pratiques : garder les pieds sur terre
Même une solution on-premise a ses défis.
Hallucinations : Les LLMs peuvent "inventer" des informations. Le RAG réduit ce risque mais ne l'élimine pas. Formez les utilisateurs à vérifier les sources fournies par le chatbot.
Coût matériel : Les GPUs nécessaires pour des performances optimales peuvent représenter un investissement initial significatif. Calculez bien votre ROI.
Éco-conception : Les LLMs sont énergivores. Optimisez vos modèles (quantization), éteignez les ressources inutilisées, et choisissez du matériel éco-énergétique lorsque possible.
Mises à jour : Maintenez à jour tous les composants : OS, base vectorielle, moteur de LLM, et les modèles eux-mêmes (avec prudence et tests).
Feedback utilisateur : Mettez en place un canal pour que les utilisateurs signalent les réponses incorrectes ou problématiques.
Conclusion : maîtrisez votre IA, protégez vos données
Créer un chatbot interne sécurisé pour vos données sensibles est un projet ambitieux, mais réalisable et de plus en plus nécessaire. En privilégiant une architecture 100 % locale, en chiffrant vos données, en contrôlant finement les accès via un RAG couplé à votre RBAC, et en assurant une gouvernance rigoureuse, vous pouvez exploiter la puissance de l'IA générative sans compromettre la confidentialité de vos informations stratégiques. C'est un investissement dans votre souveraineté numérique, votre efficacité et la confiance de vos collaborateurs.
Prêt à relever le défi ? Vous voulez savoir comment mettre votre propre un chatbot ? Nous avons une formation complète qui explique comment créer et déployer des applications d'IA générative ici !
💙 Merci d'avoir parcouru l'article jusqu'à la fin !
Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.