Construisez des pipelines de données robustes, scalables et prêts pour la production. Devenez un ingénieur data capable de concevoir, déployer et industrialiser des architectures modernes cloud & Big Data.
Vous cherchez un outil open-source pour extraire efficacement du contenu web dans un workflow RAG ou un pipeline de données IA ? Firecrawl et Crawl4AI sont deux candidats incontournables. Ces frameworks ont été conçus non pas pour le SEO ou la veille concurrentielle, mais pour l’ingestion de données textuelles à grande échelle, compatibles avec des usages LLM-first.
Firecrawl, écrit en TypeScript, propose un crawler à la fois rapide, modulaire et facile à connecter à des API comme LangChain. Crawl4AI, développé en Python, mise sur la scalabilité via Ray ou Spark, et se positionne comme un framework RAG-ready pour les ingénieurs data.
Leur comparaison est naturelle : tous deux sont self-hosted, open-source, pensés pour les développeurs, et intégrables dans des stacks modernes de traitement de documents.
Une philosophie open-source, mais des approches bien distinctes
Sous leurs licences permissives (MIT pour Firecrawl, Apache 2.0 pour Crawl4AI), ces outils incarnent deux visions :
Firecrawl privilégie la performance brute, la rapidité de déploiement, et la simplicité d’appel via API ;
Crawl4AI parie sur l’extensibilité Python, le contrôle fin sur la logique de parsing, et une intégration fluide avec les frameworks IA du moment.
Dans ce duel, tout dépend donc de votre langage de prédilection, de vos contraintes d’infrastructure, et du niveau de personnalisation requis.
TL;DR : Firecrawl et Crawl4AI sont deux frameworks open-source
conçus pour l’exploration web à grande échelle. Le premier se distingue
par sa vitesse et son support multi-langages, tandis que le second mise
sur une intégration fine avec Python, LangChain et Ray. Ce duel
s’adresse aux développeurs qui cherchent un outil auto-hébergé,
modulable, et taillé pour les pipelines RAG.
Firecrawl : la fusée multi-langages
Un crawler rapide, écrit en TypeScript, pensé pour la performance
Firecrawl est un framework d'exploration web moderne conçu pour la vitesse. Écrit en TypeScript, il peut être auto-hébergé ou appelé via une API SaaS, selon les besoins. Son principal atout : la latence ultra-faible, grâce à une architecture pensée pour les crawls massifs, même sur des machines modestes.
L’outil peut analyser une page entière, suivre les redirections, ignorer les balises robots.txt, et générer un rendu complet HTML, texte ou JSON structuré en un seul appel. Firecrawl est donc particulièrement adapté aux projets qui exigent une grande rapidité d’indexation, comme les assistants IA ou les moteurs internes à forte volumétrie.
Testé sur des jeux de données RAG, Firecrawl a montré des performances de crawling jusqu’à 10× plus rapides que certaines alternatives Python (Firecrawl, 2024 – firecrawl.dev).
Firecrawl brille par son API unique capable de retourner des formats multiples, ce qui en fait une excellente source d’entrée pour les pipelines LLM. Il s’intègre nativement avec LangChain, notamment grâce à un connecteur officiel., ce qui facilite la création d’agents autonomes chargés d’aller chercher l’information sur le web.
Autres points forts :
Rendu SSR (rendered HTML complet) compatible avec JS dynamique ;
Gestion automatique des erreurs réseau (timeouts, refus, 403) ;
Support natif de plusieurs langues (UTF-8, UTF-16, etc.).
Limites : debug complexe, configuration avancée
Mais Firecrawl n’est pas parfait. Son backend TypeScript, bien que performant, peut rebuter les équipes non familières avec Node.js. De plus, le debugging avancé est moins documenté, notamment en cas d’erreurs réseau non triviales ou de sites protégés par des anti-bot.
Autre point d'attention : Firecrawl utilise des proxys tiers pour contourner certains blocages, ce qui peut poser des questions de confidentialité dans des contextes RGPD sensibles.
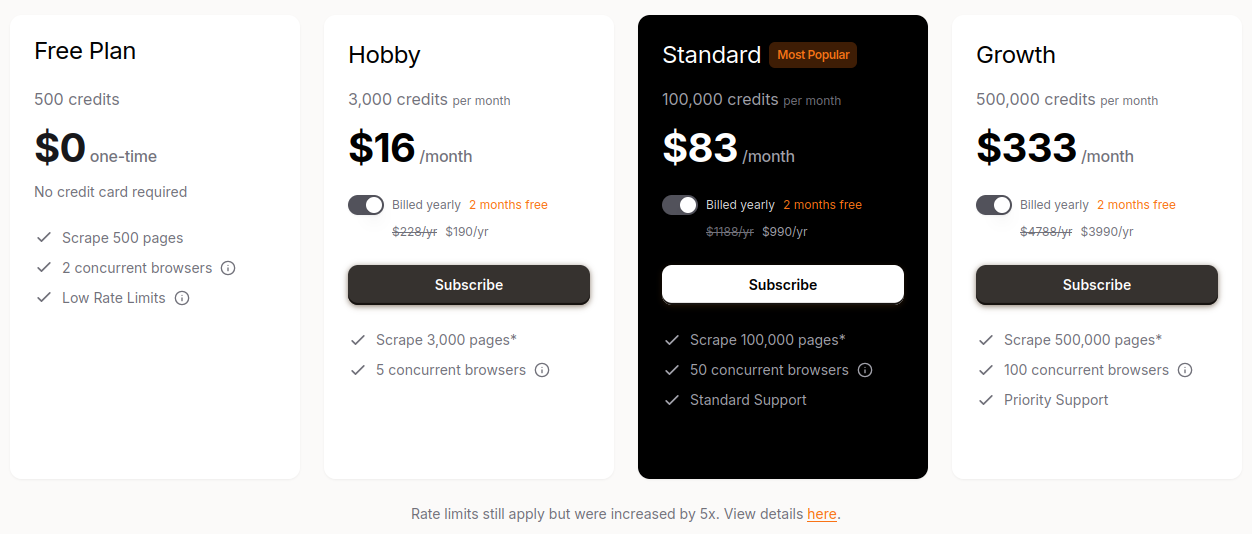
Prix
Crawl4AI : la scalabilité pensée Python
Un outil Python natif avec Ray & Spark pour le scale-out
Crawl4AI est un framework open-source écrit en Python, conçu dès le départ pour l’intégration dans des workflows IA complexes. Là où Firecrawl privilégie la vitesse brute, Crawl4AI propose une architecture pensée pour l’orchestration distribuée, en particulier via Ray ou Apache Spark.
Ce choix le rend idéal pour des pipelines où l’on souhaite crawler des milliers de pages, tout en appliquant des règles fines de parsing, de nettoyage et d’enrichissement sémantique.
Crawl4AI s’intègre facilement avec les systèmes distribués, permettant le traitement parallèle de millions de documents sans goulot d’étranglement.
Crawl4AI expose une interface Python flexible, qui permet aux utilisateurs de :
Définir leurs propres extracteurs (HTML, JSON, CSS, XPath…) ;
Ajouter des modules de post-traitement (résumés, embeddings, classification) ;
Connecter directement le framework à des moteurs vectoriels ou à des orchestrateurs comme LangChain, LlamaIndex ou Haystack.
Son principal avantage : la logique est personnalisable à tous les niveaux, ce qui le rend particulièrement adapté aux projets RAG en production, notamment dans des environnements cloud comme Azure ou AWS.
Limites : moins mature, nécessite tuning
Cependant, Crawl4AI souffre encore d’un manque relatif de maturité. Sa documentation reste sommaire, son installation demande quelques ajustements, et les performances par défaut peuvent varier selon le cluster utilisé.
L’autre point faible : pour bénéficier pleinement de ses capacités distribuées, il faut déjà maîtriser des technologies comme Ray, Spark ou les queues de messages (Kafka, Redis). Ce n’est donc pas l’outil le plus plug-and-play pour une équipe junior ou une startup en phase d’exploration.
Tableau comparatif : Firecrawl vs Crawl4AI
Critères : performance, scalabilité, prise en main, communauté
Plus restreinte, doc minimale, open-source Apache 2.0
Licence
AGPL (auto-hébergé)
Apache 2.0
Analyse rapide
🏁 Firecrawl est idéal si vous cherchez une vitesse maximale, une API simple et un rendu prêt à l’emploi pour ingestion IA.
⚙️ Crawl4AI se démarque par sa souplesse de customisation, notamment en Python, et sa capacité à scaler horizontalement.
Le choix dépend donc surtout de votre niveau technique, de vos besoins d’intégration IA et de la charge prévue. Firecrawl est plus immédiat ; Crawl4AI, plus modulable.
Quel outil choisir selon votre cas d’usage ?
Pour un scraping rapide, low-cost et plug-and-play
Vous avez besoin d’extraire du contenu web rapidement, avec un minimum de configuration ? Firecrawl est probablement le meilleur choix. Sa simplicité d’appel via une API HTTP, son rendu dynamique complet et son intégration directe avec LangChain ou Zapier en font un outil de choix pour les startups, les équipes produit ou les projets en proof-of-concept.
De plus, Firecrawl peut fonctionner sans infrastructure lourde : un conteneur Docker suffit, ou vous pouvez même utiliser leur API SaaS pour tester sans rien installer. Parfait pour démarrer vite.
Firecrawl permet de crawler une centaine de pages en moins d’une minute sur un simple serveur VPS (Firecrawl, 2024).
Pour une intégration fine dans un pipeline RAG Python
Si votre stack est orientée Python, que vous manipulez des volumes importants, ou que vous cherchez à enrichir chaque document avec du pré-traitement NLP, alors Crawl4AI devient très pertinent.
Son intégration naturelle avec des frameworks comme Ray ou Spark le rend plus adapté aux pipelines RAG en production, notamment lorsqu'on doit extraire, enrichir, vectoriser puis stocker des documents à grande échelle. Il permet également d'insérer vos propres parsers ou post-process via simples fonctions Python.
Conclusion : deux outils puissants, deux ADN bien distincts
Le duel entre Firecrawl et Crawl4AI illustre bien les deux grandes approches du scraping web open-source à l’ère de l’IA générative : d’un côté, Firecrawl offre une solution ultra-rapide, facile à intégrer via une API unique ; de l’autre, Crawl4AI propose une boîte à outils modulaire en Python, idéale pour des pipelines scalables et personnalisables.
Si vous cherchez un outil performant, simple à déployer, Firecrawl est un excellent choix. En revanche, si votre priorité est la flexibilité et l’intégration profonde dans votre stack RAG, Crawl4AI sera plus adapté.
Dans tous les cas, ce comparatif Firecrawl vs Crawl4AI montre qu’il n’est plus nécessaire de choisir entre efficacité et liberté. L’open-source offre désormais des alternatives solides, adaptées à tous les niveaux d’exigence technique.
👉 Et vous, dans votre prochain projet RAG, plutôt fusée TypeScript ou scalabilité Python ?
Vous hésitez encore ou avez besoin d'un accompagnement spécifique, notre équipe est à votre écoute
Partager avec
💙 Merci d'avoir parcouru l'article jusqu'à la fin !
Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.