Les commandes SQL essentielles pour les développeurs
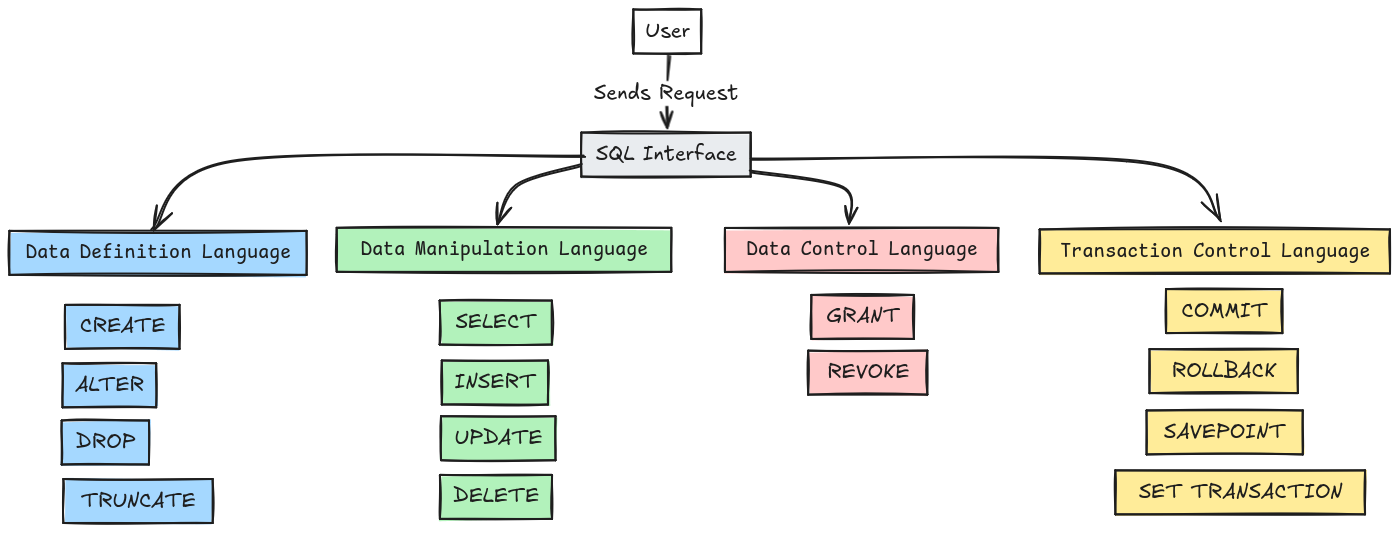
Dans le monde du développement logiciel, la manipulation des bases de données est une compétence cruciale. Que vous soyez un développeur débutant ou expérimenté, la maîtrise des commandes SQL (Structured Query Language) est essentielle pour interagir efficacement avec les bases de données relationnelles. Cet article est conçu comme un guide de référence rapide, couvrant les dix commandes SQL les plus importantes que chaque développeur devrait connaître.
Pourquoi apprendre SQL ?
L'apprentissage du SQL permet aux développeurs de créer, lire, mettre à jour et supprimer des données dans une base de données. En comprenant ces commandes fondamentales, vous serez en mesure de gérer des bases de données de manière efficace, optimiser les requêtes pour de meilleures performances, et assurer l'intégrité et la sécurité des données.
À quoi s'attendre
Nous allons explorer chaque commande avec des exemples pratiques et des cas d'utilisation concrets. De SELECT à TRANSACTION, chaque commande sera expliquée en détail, vous fournissant les connaissances nécessaires pour les appliquer dans vos projets quotidiens. Préparez-vous à améliorer vos compétences en SQL et à devenir un développeur plus efficace et polyvalent.
SELECT et ses variantes
La commande SELECT est probablement la commande SQL la plus utilisée. Elle permet de récupérer des données spécifiques dans une ou plusieurs tables d'une base de données. Voici quelques exemples d'utilisation de la commande SELECT et ses variantes.
SELECT basique
La syntaxe de base pour une requête SELECT est la suivante :
Par exemple, pour sélectionner les noms et âges des utilisateurs dans une table utilisateurs, vous pouvez utiliser :
SELECT avec conditions
Pour filtrer les résultats, vous pouvez ajouter une clause WHERE :
Cela sélectionnera seulement les utilisateurs âgés de plus de 18 ans.
SELECT avec tri
Vous pouvez trier les résultats en utilisant la clause ORDER BY :
Cela triera les utilisateurs par âge décroissant.
SELECT avec jointures
Pour récupérer des données de plusieurs tables, vous pouvez utiliser des jointures :
Cette requête sélectionne les noms des utilisateurs et les produits commandés.
INSERT et UPDATE pour la gestion des données
Les commandes INSERT et UPDATE sont essentielles pour gérer les données dans une base de données. Elles vous permettent respectivement d'ajouter de nouvelles entrées et de mettre à jour les entrées existantes.
INSERT
La commande INSERT permet d'ajouter de nouvelles lignes dans une table. Voici un exemple de syntaxe de base :
Par exemple, pour ajouter un nouvel utilisateur dans la table utilisateurs, vous pouvez utiliser :
UPDATE
La commande UPDATE permet de modifier des entrées existantes. Voici un exemple de syntaxe de base :
Pour mettre à jour l'âge d'un utilisateur spécifique, vous pouvez utiliser :
Bonnes pratiques
- Toujours utiliser une clause : Pour éviter les mises à jour ou insertions accidentelles sur toutes les lignes.
- Vérifier les valeurs : S'assurer que les valeurs insérées ou mises à jour respectent les contraintes de la table.
DELETE et TRUNCATE pour la suppression des données
La gestion des données implique aussi leur suppression, et les commandes DELETE et TRUNCATE sont utilisées à cette fin. Bien qu’elles aient des objectifs similaires, elles fonctionnent différemment et sont utilisées dans des contextes différents.
DELETE
La commande DELETE permet de supprimer des lignes spécifiques d'une table selon une condition donnée. Voici un exemple de syntaxe :
Par exemple, pour supprimer un utilisateur nommé Alice de la table utilisateurs, vous pouvez utiliser :
Cette commande supprime uniquement les lignes qui satisfont la condition.
TRUNCATE
La commande TRUNCATE permet de supprimer toutes les lignes d'une table, mais conserve la structure de la table pour des insertions futures. Voici un exemple de syntaxe :
Par exemple, pour supprimer toutes les entrées de la table utilisateurs, vous pouvez utiliser :
Différences clés
DELETE peut être utilisé avec une clause WHERE pour cibler des lignes spécifiques.TRUNCATE est plus rapide mais ne peut pas être utilisé pour supprimer des lignes spécifiques, seulement toutes les lignes de la table.
JOIN et les différentes types de jointures
Les jointures (JOIN) sont utilisées pour combiner des lignes de deux ou plusieurs tables en fonction d'une condition commune. Voici quelques types de jointures couramment utilisés et leurs exemples.
INNER JOIN
L'INNER JOIN retourne seulement les lignes où il y a une correspondance dans les deux tables. Voici un exemple :
Cela sélectionne les noms des utilisateurs et la date des commandes où il existe une correspondance.
LEFT JOIN
Le LEFT JOIN retourne toutes les lignes de la table de gauche, et les lignes correspondantes de la table de droite. Si aucune correspondance n'est trouvée, les résultats de la table de droite seront NULL.
RIGHT JOIN
Le RIGHT JOIN fonctionne de la même manière que le LEFT JOIN, mais retourne toutes les lignes de la table de droite et les lignes correspondantes de la table de gauche.
FULL JOIN
Le FULL JOIN retourne toutes les lignes où il y a une correspondance dans une des tables. Les résultats non correspondants des deux tables auront des valeurs NULL.
Les fonctions agrégées essentielles
Les fonctions agrégées permettent de réaliser des calculs sur un ensemble de valeurs et de retourner une seule valeur. Elles sont particulièrement utiles pour les rapports et les analyses de données. Voici quelques fonctions agrégées essentielles.
COUNT
La fonction COUNT retourne le nombre de lignes qui correspondent à une condition spécifiée. Par exemple, pour compter le nombre d'utilisateurs dans la table utilisateurs :
SUM
La fonction SUM retourne la somme des valeurs d'une colonne numérique. Par exemple, pour calculer le total des montants de toutes les commandes :
AVG
La fonction AVG retourne la moyenne des valeurs d'une colonne. Par exemple, pour calculer l'âge moyen des utilisateurs :
MAX et MIN
Les fonctions MAX et MIN retournent respectivement la valeur maximale et minimale d'une colonne. Par exemple, pour trouver l'âge le plus élevé et le plus bas des utilisateurs :
Clauses WHERE et HAVING
Les clauses WHERE et HAVING sont utilisées pour filtrer les résultats d'une requête SQL afin de ne retourner que les lignes qui répondent à certaines conditions.
Clause WHERE
La clause WHERE est utilisée pour filtrer les lignes avant l'agrégation des données. Elle s'applique généralement aux colonnes individuelles et aux conditions de base. Par exemple, pour sélectionner les utilisateurs âgés de plus de 18 ans :
Vous pouvez également utiliser des opérateurs logiques comme AND, OR pour combiner plusieurs conditions :
Clause HAVING
La clause HAVING est utilisée pour filtrer les résultats après l'agrégation des données. Elle est souvent utilisée avec les fonctions agrégées comme COUNT, SUM, AVG, etc. Par exemple, pour sélectionner les villes ayant plus de 10 utilisateurs :
La clause HAVING permet de spécifier des conditions sur les groupes de résultats générés par la clause GROUP BY. En combinant WHERE et HAVING, vous pouvez affiner encore plus vos requêtes SQL.
Utilisation des sous-requêtes
Les sous-requêtes, ou requêtes imbriquées, sont des requêtes SQL incluses dans une autre requête SQL. Elles permettent de réaliser des requêtes plus complexes et de filtrer les résultats en fonction des données d'une autre table.
Sous-requête dans une clause SELECT
Une sous-requête peut être utilisée dans une clause SELECT pour retourner une valeur calculée. Par exemple, pour sélectionner les utilisateurs et leur commande la plus récente :
Sous-requête dans une clause WHERE
Une sous-requête peut également être utilisée dans une clause WHERE pour filtrer les résultats en fonction d'une autre requête. Par exemple, pour sélectionner les utilisateurs ayant passé des commandes :
Sous-requête dans une clause FROM
Une sous-requête peut être utilisée dans une clause FROM pour créer une table temporaire. Par exemple, pour sélectionner les utilisateurs et le total de leurs commandes :
Gestion des transactions avec COMMIT et ROLLBACK
La gestion des transactions est cruciale pour garantir l'intégrité des données dans une base de données. Les commandes COMMIT et ROLLBACK permettent de contrôler les transactions, assurant que les opérations de modification des données sont effectuées de manière atomique.
Débuter une transaction
Pour commencer une transaction, utilisez la commande BEGIN ou START TRANSACTION :
Toutes les opérations de modification des données après cette commande font partie de la transaction.
COMMIT
La commande COMMIT permet de valider toutes les opérations réalisées dans une transaction, les rendant permanentes dans la base de données :
Utilisez cette commande à la fin de votre transaction pour vous assurer que les modifications sont enregistrées.
ROLLBACK
La commande ROLLBACK permet d'annuler toutes les opérations réalisées depuis le début de la transaction, restaurant la base de données à son état initial avant la transaction :
Utilisez cette commande en cas d'erreur ou si une condition de la transaction n'est pas remplie, garantissant ainsi l'intégrité des données.
Exemple pratique
Voici un exemple combinant ces commandes :
Si une erreur survient, utilisez ROLLBACK pour annuler les modifications.
Aller plus loin
Vous souhaitez approfondir vos compétences en SQL et en bases de données ? Découvrez nos formations en ligne :









