Construisez des pipelines de données robustes, scalables et prêts pour la production. Devenez un ingénieur data capable de concevoir, déployer et industrialiser des architectures modernes cloud & Big Data.
TL;DR : Firecrawl, projet open-source auto-hébergeable, brille par sa vitesse, sa flexibilité et ses intégrations RAG. Spider, solution SaaS plug-and-play, séduit par sa simplicité d’usage et ses performances prêtes à l’emploi. Le bon choix dépend de vos contraintes d’infrastructure, de budget et de contrôle sur les données.
Dans un pipeline RAG (Retrieval-Augmented Generation), la qualité de l’ingestion web est critique. Et qui dit ingestion, dit crawler intelligent. Deux outils se démarquent aujourd’hui dans l’écosystème IA : Firecrawl et Spider.
Le premier, Firecrawl, propose un modèle hybride : open-source (licence AGPL-3.0) et SaaS modulaire, idéal pour ceux qui veulent maîtriser leur infrastructure tout en gardant une option cloud. Le second, Spider, est un service entièrement hébergé, pensé pour l’efficacité immédiate : une API, un appel, des données LLM-ready.
Pourquoi les comparer ? Parce qu’ils incarnent deux visions opposées mais complémentaires :
Firecrawl vise la vitesse brute, la modularité et l’auto-hébergement.
Spider offre la simplicité d’usage, l’orchestration cloud et un rendu toujours propre.
Dans un contexte où les modèles de langage doivent rester à jour, le choix du bon outil de crawl web peut faire gagner — ou perdre — des heures. Ce guide vous aide à choisir l’outil qui correspond à votre budget, vos contraintes techniques, et vos ambitions IA.
Vue d’ensemble : deux philosophies du web crawling LLM-ready
Firecrawl est un projet open-source sous licence AGPL-3.0, porté par Mendable. Il peut être auto-hébergé ou utilisé via un service SaaS freemium. Son architecture est pensée pour la scalabilité industrielle, avec un support natif de LangChain, LlamaIndex et autres frameworks RAG. Firecrawl propose une interface CLI, une API REST, et un SDK dans plusieurs langages (Python, JS, Go, Rust), en plus d’un loader LangChain officiel (Firecrawl, 2024).
De l’autre côté, Spider est un service cloud 100 % SaaS, sans code open-source. Il mise tout sur le plug-and-play : une API REST, une interface web conviviale, et des SDK clients pour Python et JavaScript. Il propose lui aussi un SpiderLoader intégré à LangChain, pour des chaînes d’agents prêtes à fonctionner en quelques lignes (Spider, 2024).
Critère
Firecrawl
Spider
Licence
AGPL-3.0 (self-host) / SaaS
Propriétaire, uniquement SaaS
Déploiement
Local ou Cloud
100 % cloud
Langages supportés
Python, JS, Go, Rust
Python, JavaScript
Intégration LLM
LangChain, LlamaIndex, Flowise, Dify…
LangChain (SpiderLoader), AutoGPT, etc.
Interface
CLI, playground, API REST
Dashboard, API REST
Approche
Contrôle, vitesse, flexibilité
Simplicité, rapidité, zéro maintenance
En résumé, Firecrawl est un outil d’ingénieur, taillé pour les stacks personnalisées, tandis que Spider s’adresse aux développeurs qui veulent aller vite sans configurer quoi que ce soit.
Coût et modèle économique : flexibilité contre forfait
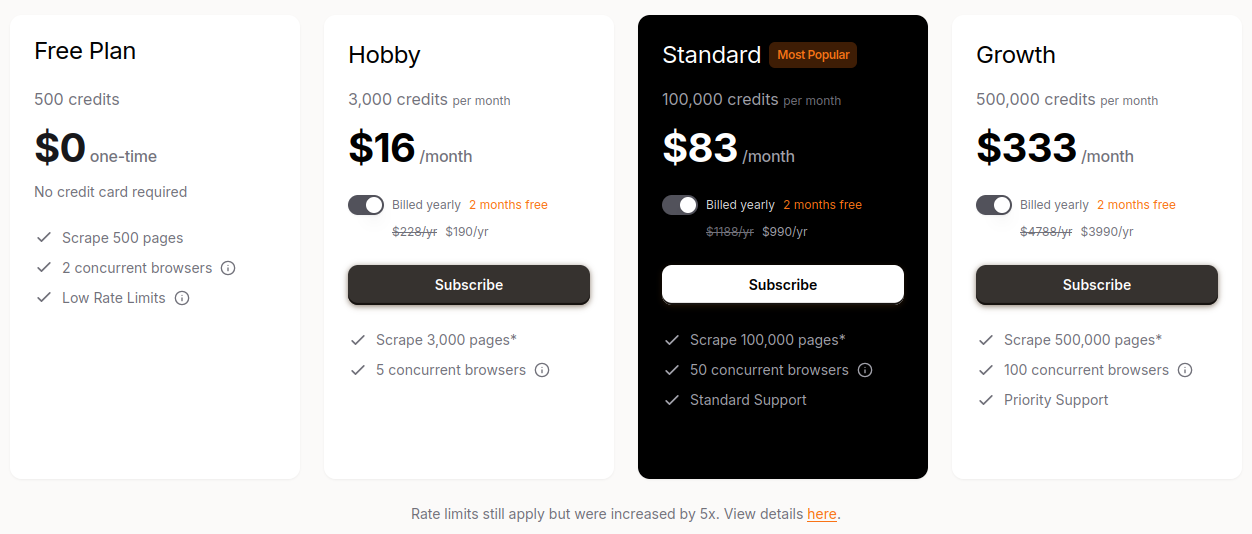
Le modèle économique de Firecrawl reflète sa nature hybride. Le code est open-source sous AGPL-3.0, ce qui permet une auto-hébergement sans frais… à condition de respecter la licence (obligation de republier les modifications si l’outil est exposé publiquement). Pour les projets sans infrastructure, Firecrawl propose une API cloud en freemium avec 500 crédits gratuits et des forfaits à partir de 16 $/mois, évolutifs selon les volumes (Firecrawl, 2024).
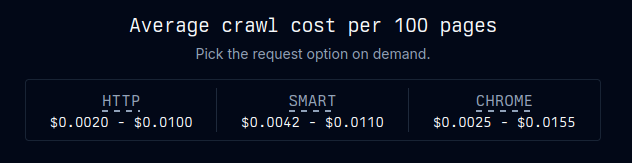
Spider, de son côté, est 100 % SaaS, avec un free tier limité (nombre de pages/mois) puis des plans tarifés selon le nombre de pages crawlées, la profondeur de crawl et la vitesse. Le positionnement revendique être plus économique que d’autres services du marché (note 7/10 sur l’“affordability” dans un benchmark ScrapeGraphAI : Spider, 2024).
Comparatif économique simplifié :
Éléments
Firecrawl
Spider
Licence open-source
Oui (AGPL-3.0)
Non
Coût d’entrée SaaS
~16 $/mois (après free tier)
Quelques dizaines de $/mois
Free tier
500 pages/mois environ
Limité à quelques centaines de pages
Facturation
Par page, avec options avancées
Par palier mensuel selon volume
Évolutivité
Flexible (open-source ou abonnements)
Scalabilité cloud incluse
Latence et performance brute : rapidité vs fluidité
Côté performance brute, Firecrawl mise sur une architecture taillée pour le volume. Grâce à un moteur optimisé en parsing DOM (sans appel LLM) et un rendu JavaScript via Playwright, il peut traiter des milliers de pages en parallèle, localement ou en cloud. En auto-hébergé, sa vitesse dépend de vos ressources ; en SaaS, il affiche des performances jusqu’à 4× plus rapides que certains concurrents LLM-driven (Firecrawl, 2024).
De son côté, Spider repose sur une infrastructure distribuée. Son point fort : une latence très faible par page, grâce à un système de proxies haute performance, cache AI et solveurs CAPTCHA intégrés. En mode SaaS, Spider garantit une vitesse constante, sans goulot d’étranglement, même sur des crawls profonds. Le tout sans configuration serveur, avec des webhooks de fin de traitement pour une intégration fluide dans vos pipelines (Spider, 2024).
Synthèse des performances :
Critère
Firecrawl
Spider
Rendu JavaScript
Playwright intégré, interactions dynamiques
Headless + IA, solve CAPTCHA
Vitesse de crawl
Très rapide (batch, multithread)
Ultra-rapide (SaaS distribué)
Parallélisme
Threads + cluster local/cloud
Géré automatiquement par l’infra Spider
Cache / retries
Mécanismes intégrés + anti-blockers
Cache AI + détection automatique d’erreurs
Latence unitaire
Très bonne, dépend de l’hébergement
Excellente, scalable sans effort
🧠 À noter :
Si vous cherchez à crawler un gros corpus rapidement avec peu de frais, Firecrawl en local est un choix redoutable.
Si vous voulez des résultats instantanés sans déployer quoi que ce soit, Spider est plus fluide et linéaire.
Envie de vous former à l'Ia générative ?
Intégration dans un pipeline RAG : le match des loaders
L’intégration dans les frameworks LLM est un critère clé lorsqu’on construit un pipeline RAG. Sur ce point, Firecrawl fait figure de champion : il propose des loaders officiels pour LangChain (Python et JS), LlamaIndex (WebPageReader dédié), et s’intègre même dans des outils no-code comme Dify, Flowise ou Langflow. En Python, un simple FireCrawlLoader(url) suffit à charger une page en mode “scrape” ou “crawl”, puis l’envoyer dans votre chaîne RAG (Firecrawl, 2024).
Spider, en tant que solution SaaS moderne, n’est pas en reste. Il propose également des loaders pour LangChain dans les deux langages (SpiderLoader). L’appel à l’API peut se faire depuis n’importe quelle stack grâce à un SDK JS/Python ou une API REST universelle. On apprécie les webhooks de fin de tâche, utiles pour orchestrer les flux : quand un crawl est fini, on reçoit l’alerte, prête à être branchée à un résumé, un embedding ou un envoi en base vectorielle (Spider, 2024).
Intégrations LLM/RAG en résumé :
Fonction
Firecrawl
Spider
Loader LangChain (Python + JS)
Oui (officiel, FireCrawlLoader)
Oui (officiel, SpiderLoader)
Compatibilité LlamaIndex
Oui (via WebPageReader personnalisé)
Non natif, possible via Markdown JSON
Orchestration No/Low-code
Oui (Dify, Langflow, Flowise)
Non (mais API/webhooks faciles à intégrer)
API REST
Oui
Oui
Réception automatique des données
Non (pull mode uniquement)
Oui (webhook en push)
💡 Conseil :
Si vous montez un pipeline LangChain sophistiqué, Firecrawl offre plus de flexibilité et de compatibilité directe.
Si vous avez un flux déclenché à la volée (agent, bot, plugin), Spider est conçu pour ça, avec sa logique API → Résultat → Webhook.
Gestion des proxies et du JavaScript dynamique
Quand il s’agit de crawler des sites modernes, le support du JavaScript, des proxies et des techniques anti-bot devient essentiel. Sur ce plan, Firecrawl se distingue par son approche robuste : il intègre Playwright, permettant de rendre les pages côté client, de cliquer, scroller, ou d’attendre le chargement AJAX. Pour passer les protections, il embarque une gestion fine : proxies rotatifs, headers personnalisés, timing aléatoire, et même la simulation d’interaction utilisateur (Firecrawl, 2024).
De son côté, Spider mise sur la transparence et la simplicité : vous ne gérez rien. L’infrastructure Spider applique automatiquement rotation d’IP, solveurs CAPTCHA intégrés et même des actions pilotées par IA. Ces dernières permettent par exemple de cliquer dynamiquement sur un onglet ou un bouton “voir plus”, si l’IA estime qu’il faut accéder à un contenu caché. Cette fonction est précieuse pour les interfaces SPA ou les sites à contenu conditionnel (Spider, 2024).
Comparatif technique :
Fonctionnalité
Firecrawl
Spider
Support JavaScript
Oui (Playwright intégré)
Oui (headless automatisé)
Interaction avec la page
Simulations manuelles (clics, scroll…)
Actions AI automatiques
Rotation de proxies / IP
Configurable, manuelle ou scriptée
Automatique, incluse dans le SaaS
Gestion CAPTCHA
Non intégrée (à faire côté infra)
Intégrée (solveur embarqué)
Protection contre blocage
Headers, délais randomisés, retry
Invisible pour l’utilisateur
🔐 À retenir :
Firecrawl donne le contrôle complet : idéal pour les experts qui doivent crawler des environnements complexes ou très protégés.
Spider offre une expérience sans friction : aucune configuration, même sur des sites « pénibles ».
Respect de robots.txt et conformité RGPD
Dans tout projet d’ingestion web — surtout pour une utilisation avec des LLM — la conformité est un enjeu aussi technique que juridique. Sur ce terrain, Firecrawl se veut transparent et configurable : par défaut, il respecte les règles définies dans les fichiers robots.txt des sites visités, mais l’utilisateur peut désactiver cette restriction s’il l’assume. Les logs d’activité incluent URL, timestamps et statut, ce qui facilite la traçabilité et la revue a posteriori. Firecrawl ne stocke aucune donnée en SaaS au-delà du nécessaire pour le traitement, et les exports incluent les liens sources, ce qui facilite la citation dans un contexte LLM (Firecrawl, 2024).
Spider, en tant que service SaaS, applique également les bonnes pratiques de scraping responsable : respect des délais entre requêtes, adhésion aux règles robots.txt, et identification claire des requêtes. Mais contrairement à Firecrawl, l’utilisateur ne contrôle pas ces paramètres finement. Côté RGPD, Spider n’enregistre que temporairement les données extraites, et renvoie l’URL source avec le contenu, ce qui peut être utile pour documenter la provenance. En revanche, vous devez faire confiance à l’infrastructure Spider pour tout ce qui concerne la gestion des données sensibles (Spider, 2024).
Comparatif conformité & éthique :
Critère
Firecrawl
Spider
Respect robots.txt
Oui (modifiable par l’utilisateur)
Oui (par défaut, non personnalisable)
Traçabilité des URLs
Oui (logs détaillés, liens dans l’export)
Oui (URLs dans la réponse)
Stockage cloud des données
Non (temporaire et limité si SaaS)
Temporaire (gestion interne opaque)
RGPD & responsabilités
À la charge de l’utilisateur
À vérifier selon l’usage
Citation automatisée
Possible (liens dans le Markdown exporté)
Possible (source URL toujours présente)
⚖️ Conseil :
Firecrawl est à privilégier si vous devez gérer finement la conformité ou auditer les flux de crawl.
Spider est suffisant pour des usages “light” ou dans un environnement sous contrôle (pages publiques, peu sensibles).
Cas d’usage typiques : du prototypage RAG au chatbot production
Firecrawl s’impose comme un outil de référence pour les projets RAG nécessitant l’ingestion massive de contenu web. Parmi ses usages fréquents :
Construire une base de connaissances pour un chatbot documentaire, en aspirant tout un site en Markdown.
Effectuer de la veille concurrentielle, en extrayant automatiquement les fiches produit ou les articles de blog de vos rivaux.
Mettre en place des pipelines de résumé (crawl → LLM → base vectorielle), par exemple pour résumer la documentation d’un outil ou les FAQ d’un service.
Gérer des sites complexes : Firecrawl supporte les SPAs, AJAX et scrolls infinis, utiles pour capturer du contenu que d’autres outils ignorent.
De son côté, Spider est pensé pour des cas où la réactivité prime :
Intégration dans un agent IA conversationnel, qui lit une page à la volée selon une question utilisateur.
Indexation rapide d’un site web, sans installer quoi que ce soit : une API call et l’on obtient du Markdown structuré, prêt à vectoriser.
Extraction multi-sites (tarifs, produits, annonces, etc.) grâce à la vitesse et la stabilité de l’API.
Usage dans des environnements sans DevOps : startups, growth teams ou équipes produit qui veulent un résultat immédiat.
Exemples d’utilisation concrets :
Besoin métier
Outil recommandé
Pourquoi
Créer une base RAG sur toute une doc
Firecrawl
Export Markdown propre, découpage par sections
Scraper plusieurs pages de résultats
Firecrawl
Scroll infini, simulation clics, proxies
Alimenter un bot avec des pages live
Spider
API simple + latence minimale
Indexer un blog pour moteur de recherche
Spider
Crawl + structuration + webhooks automatiques
Faire un POC de recherche vectorielle
Firecrawl
Freemium, Markdown LLM-ready directement
🛠️ À retenir :
Firecrawl brille sur les projets structurés, avec besoin de contrôle, qualité et scalabilité.
Spider excelle dans les projets agiles, où vitesse et simplicité sont prioritaires.
Que choisir ? Scénarios recommandés selon vos besoins
Choisir entre Firecrawl et Spider, ce n’est pas simplement trancher entre open-source et SaaS — c’est définir votre stratégie d’ingestion dans un pipeline RAG. Voici les principaux scénarios d’usage pour vous guider.
Scénarios où Firecrawl est plus adapté :
🧩 Vous voulez un outil totalement personnalisable : via Playwright, découpage regex, choix du format (JSON, Markdown, HTML).
🛠️ Vous avez déjà une infrastructure technique (serveur, cluster, Docker, etc.).
💸 Vous souhaitez réduire les coûts à long terme avec un déploiement auto-hébergé.
🔎 Vous devez respecter des règles de conformité internes (ex. RGPD, audit, provenance des contenus).
Scénarios où Spider est la meilleure option :
⚡ Vous avez besoin de résultats immédiats, sans installation ni configuration.
🤖 Vous alimentez un assistant IA conversationnel en temps réel.
👥 Votre équipe n’a pas de DevOps : Spider gère le backend, les proxies, le JS, le scheduling.
🧪 Vous réalisez un POC rapide ou une extraction ponctuelle.
📈 Vous voulez scaler facilement, sans gérer de quota manuel ou de monitoring local.
En synthèse :
Profil utilisateur
Recommandation
Ingénieur RAG avec pipeline custom
Firecrawl
Growth hacker ou équipe produit
Spider
Projet RGPD / haute traçabilité
Firecrawl
MVP sans équipe tech
Spider
Utilisation en cluster ou notebook
Firecrawl
Conclusion : Firecrawl vs Spider, quel crawler LLM-ready pour 2025 ?
Dans l’univers en pleine explosion des workflows RAG, le choix du bon crawler web fait toute la différence. Firecrawl et Spider incarnent deux approches résolument opposées — mais également légitimes.
👉 Firecrawl est l’outil des architectes. Open-source, paramétrable, extensible, il excelle dans les projets où l’on veut tout contrôler, du proxy à l’output Markdown, avec une intégration fine dans les écosystèmes LangChain et LlamaIndex. Il s’adapte aux environnements techniques complexes, à l’automatisation poussée, et à une logique de coût long terme optimisé.
👉 Spider, à l’inverse, est l’outil des builders agiles. Il privilégie l’efficacité immédiate, avec des performances élevées dès la première API call. C’est le choix idéal pour tester une idée, prototyper un chatbot, ou gagner du temps dans des équipes sans DevOps. L’intégration à LangChain est directe, l’infrastructure est gérée, et les résultats sont exploitables à chaud.
🔎 En 2025, vous n’avez plus à choisir entre rapidité et qualité. Ces deux outils, bien que différents, peuvent même être complémentaires : Firecrawl pour l’ingestion massive périodique, Spider pour l’interrogation live ou les crawls ciblés.
Vous hésitez encore ou avez besoin d'un accompagnement spécifique, notre équipe est à votre écoute
Partager avec
💙 Merci d'avoir parcouru l'article jusqu'à la fin !
Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.