Construisez des pipelines de données robustes, scalables et prêts pour la production. Devenez un ingénieur data capable de concevoir, déployer et industrialiser des architectures modernes cloud & Big Data.
Dans le monde des workflows RAG (Retrieval-Augmented Generation), deux visions de l’exploration web s’opposent. D’un côté, Firecrawl, le sprinteur du web, ratisse des milliers de pages à une vitesse fulgurante. De l’autre, ScrapeGraphAI mise sur la finesse : extraction précise, orchestrée par des prompts en langage naturel. Alors que l’un cherche à gagner du temps, l’autre cherche à gagner en pertinence.
Ce comparatif vous aide à faire un choix éclairé : vaut-il mieux crawler vite et large, ou extraire moins mais mieux ? Dans cet article, nous décortiquons les forces et limites de chacun, avec un objectif clair : vous permettre de construire un pipeline d’ingestion web optimisé pour l’IA générative. Vous êtes architecte de RAG, data scientist ou développeur IA ? Ce duel technologique est fait pour vous.
TL;DR : Firecrawl et ScrapeGraphAI incarnent deux visions du web
scraping pour l’IA : l’un optimise la vitesse et le volume à bas coût,
l’autre maximise la pertinence par des prompts intelligents. Le choix
dépend de vos priorités : rapidité brute ou extraction précise sur
mesure ? Ce guide complet vous aide à trancher.
Firecrawl : la performance brute au service des LLM
Un crawler optimisé pour l’échelle et la vitesse
Firecrawl est un outil hybride : open-source sous licence AGPL-3.0 et disponible en SaaS via Mendable. Il est conçu pour l’ingestion massive de données web à des vitesses records, avec une approche centrée sur la performance brute plutôt que l’intelligence contextuelle. Firecrawl utilise un rendu headless (via Playwright) pour exécuter les scripts JavaScript, simuler les clics ou le scroll, et gérer les contenus dynamiques.
Il supporte le traitement batch, la concurrence élevée et les proxies rotatifs pour contourner les protections anti-crawling. L’outil privilégie des techniques classiques (regex, parsing DOM) qui le rendent 4× plus rapide que les extracteurs pilotés par LLM sur des volumes comparables (ScrapegraphAI, 2024).
Formats “LLM-ready” et intégration directe aux frameworks IA
Firecrawl se distingue par sa capacité à produire des documents prêts à indexer : Markdown propre, JSON structuré, HTML simplifié, et même capture d’écran. Il propose un découpage intelligent en chunks (sections thématiques, longueurs fixes, regex) facilitant l’indexation vectorielle directe. De plus, il s’intègre nativement à LangChain, LlamaIndex, CrewAI ou encore Flowise (Firecrawl, 2024 : firecrawl.dev/blog).
Des connecteurs dédiés comme FireCrawlLoader permettent de charger les résultats d’extraction en documents exploitables immédiatement dans des workflows RAG. Cette compatibilité directe est un atout pour une automatisation de bout en bout.
Cas d’usage typiques : documentation, veille, ingestion massive
Firecrawl est utilisé pour des cas d’usage à fort volume : ingestion de documentation produit, veille concurrentielle, analyse de contenus sur des centaines de pages. Il est idéal pour alimenter rapidement un moteur de recherche interne, scraper les articles récents d’un blog ou indexer les FAQ d’un site métier. Grâce à ses performances, Firecrawl excelle là où les scrapers traditionnels échouent – en particulier sur les SPA (Single Page Apps) ou les pages complexes.
Sa scalabilité et son orchestration (API, Zapier, file d’attente, reprise sur erreur) le rendent apte à s’intégrer dans un système d’ingestion industriel, sans effort de supervision constant.
ScrapeGraphAI : l’intelligence du prompt au service du scraping
Une approche pilotée par le langage naturel
ScrapeGraphAI propose une vision radicalement différente du web scraping : ici, l’extraction ne repose pas sur des règles fixes, mais sur des prompts en langage naturel. L’utilisateur décrit ce qu’il veut (« récupère le prix et le titre de ce produit »), et le système génère automatiquement un graphe d’actions pour y parvenir, en combinant LLM, Playwright et logique d’orchestration (ScrapeGraphAI, 2024).
L’approche est plus lente que celle de Firecrawl, mais beaucoup plus flexible : le LLM comprend la structure de la page, identifie les éléments pertinents et sait les extraire même quand l’HTML est complexe ou non conventionnel.
Extraction ciblée, multi-formats, et pipelines intelligents
ScrapeGraphAI va au-delà du simple scraping. Il permet de :
générer un script Python autonome pour reproduire l’extraction ;
réaliser des recherches sur plusieurs sites (SearchGraph) ;
résumer ou vocaliser une page via LLM (SpeechGraph) ;
scraper en parallèle plusieurs sources avec le même prompt (SmartScraperMultiGraph).
L’outil supporte HTML, JSON, Markdown et produit en sortie du texte brut ou structuré (souvent au format JSON, Markdown ou résumé). Sa précision sur l’extraction ciblée atteint jusqu’à 97,5 % selon ses créateurs – là où Firecrawl extrait tout, ScrapeGraphAI extrait juste ce qu’il faut (ScrapeGraphAI, 2024).
Cas d’usage typiques : recherche ciblée, scraping orienté données
ScrapeGraphAI est idéal pour des cas où vous avez besoin de données spécifiques : extraire les prix d’un produit sur plusieurs sites, résumer des lois sur des portails gouvernementaux, récupérer les descriptions de postes sur des plateformes RH. Il brille lorsqu’il faut comprendre le contenu avant de l’extraire.
Dans un pipeline RAG, ScrapeGraphAI est souvent utilisé en amont pour collecter des données précises, que l’on injecte ensuite dans un index vectoriel ou un knowledge graph. Son avantage ? Gagner un temps humain considérable sur l’analyse manuelle et le développement de scrapers sur-mesure.
Face-à-face technique : que vaut vraiment chaque outil ?
Rapidité de crawl, scalabilité, JS et anti-blocking
Firecrawl mise tout sur la vitesse. Son architecture distribuée, son support du multithreading, et ses optimisations côté parsing (regex, DOM) lui permettent de crawler plusieurs milliers de pages à la minute. Il exécute le JavaScript via Playwright, gère le scroll infini, les clics dynamiques et utilise des proxies rotatifs pour contourner les blocages.
ScrapeGraphAI, en revanche, est plus lent : chaque page demande un ou plusieurs appels LLM, ce qui alourdit le processus. Mais cela permet une compréhension avancée de la page. Il est capable de cliquer au bon endroit ou de générer un graphe de scraping ajusté au contenu. Sur des cibles complexes, cette lenteur devient un investissement pour la qualité.
Qualité du rendu, formats disponibles et compatibilité LLM
Firecrawl produit des documents LLM-ready directement en Markdown, HTML propre ou JSON. Il propose même un découpage logique automatique, avec des chunks adaptés à l’indexation. Il s’intègre parfaitement aux frameworks comme LangChain, LlamaIndex, Haystack, avec des loaders natifs (Firecrawl, 2024).
ScrapeGraphAI, de son côté, est plus orienté données structurées : le résultat est souvent du JSON ciblé, voire un résumé, un script Python ou une réponse audio. Il ne fournit pas de document loader LangChain prêt à l’emploi, mais peut facilement être couplé manuellement. La précision de l’extraction est son principal atout.
Facilité d’orchestration et automatisation du scraping
Firecrawl est prêt pour l’orchestration industrielle : API REST, Zapier, planification des crawls, file d’attente, reprise sur erreur. On peut le déployer sur cluster, avec reprise automatique en cas de timeout ou de blocage. Il est donc idéal pour des flux d’ingestion massifs ou récurrents.
ScrapeGraphAI est davantage une brique intelligente dans un pipeline. Il peut être couplé avec Ray, Airflow ou Docker pour orchestrer plusieurs graphes, mais il n’embarque pas de système de planification interne. Il excelle en usage ciblé, avec intervention humaine minimale grâce à sa logique "prompt-to-scraper".
Vous souhaitez vous former sur l'IA générative ?
Tarifs, licences et conformité : open-source ou SaaS ?
Firecrawl : freemium optimisé, mais sous AGPL
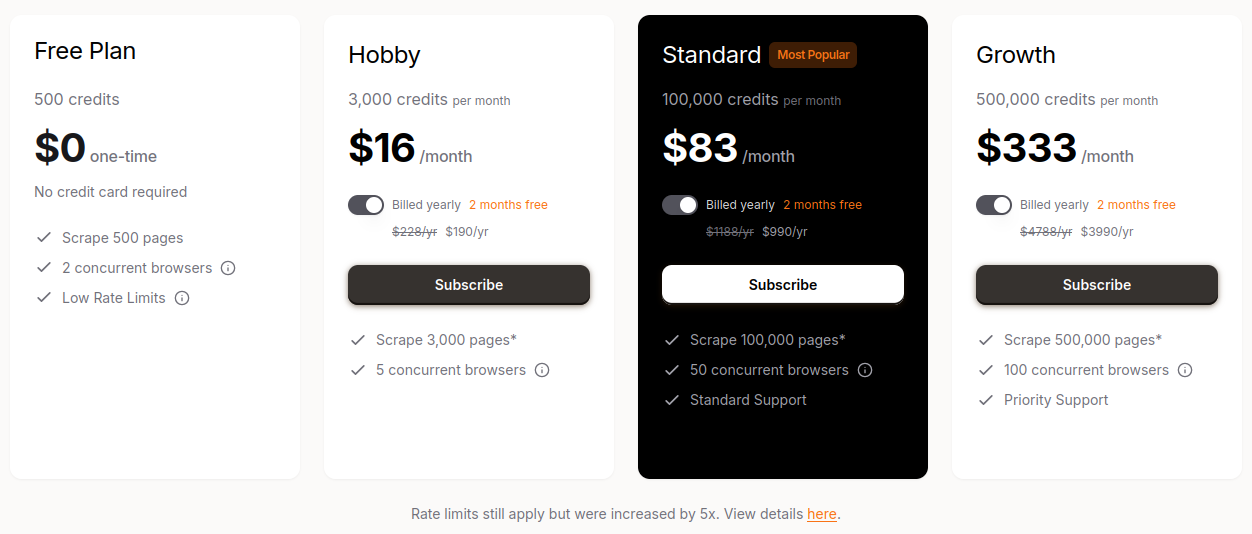
Firecrawl propose deux modèles : un code open-source sous licence AGPL-3.0 (avec obligation de publication des modifications si déployé publiquement), et un service SaaS géré par Mendable. Le plan gratuit offre quelques centaines de crédits, suffisant pour tester ou lancer de petits crawls. Ensuite, les tarifs démarrent autour de 16 $/mois, évoluant selon le volume traité (Firecrawl, 2024).
Cette approche hybride permet un déploiement flexible : en local pour les organisations sensibles à la confidentialité, ou dans le cloud pour des projets rapides. Firecrawl est pensé pour minimiser le coût par page, surtout à grande échelle – un argument marketing fort face à ScrapeGraphAI et ses coûts LLM.
ScrapeGraphAI : entièrement libre mais dépendant du coût des LLM
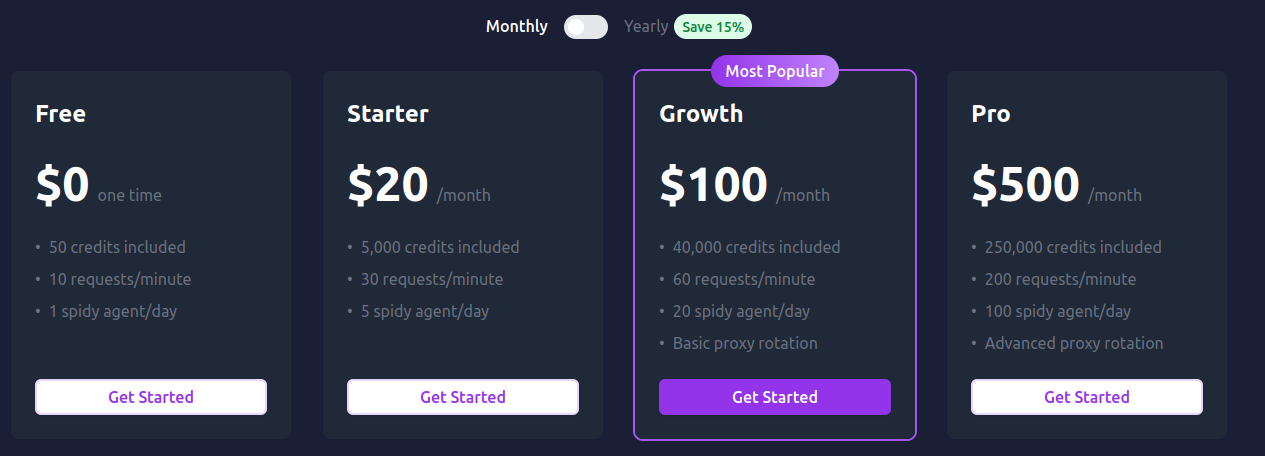
ScrapeGraphAI est 100 % open-source sous licence MIT, sans SaaS officiel. L’outil en lui-même est gratuit, mais sa dépendance aux modèles LLM (souvent payants comme GPT-4) rend son coût indirect variable. Un seul appel LLM par page peut coûter plusieurs centimes, selon le modèle utilisé.
Ainsi, pour une extraction ponctuelle, ScrapeGraphAI est ultra économique en développement humain (il génère lui-même les scripts), mais plus coûteux en exécution. Pour des volumes importants, le coût par page peut rapidement grimper, surtout avec des modèles premium.
Respect des règles d’éthique, robots.txt et RGPD
Firecrawl respecte les robots.txt par défaut, ne conserve pas les données extraites (en SaaS) au-delà du nécessaire, et fournit des logs détaillés pour la traçabilité. Il appartient toutefois à l’utilisateur de vérifier la légalité de l’usage final (RGPD, droit d’auteur, etc.). Il peut inclure automatiquement les liens sources dans le Markdown pour renforcer la transparence.
ScrapeGraphAI imite la navigation humaine (via Playwright), ce qui réduit l’impact serveur et diminue les risques d’anti-scraping. Il laisse aussi à l’utilisateur la charge du respect des règles d’exclusion et de la légalité du traitement. Sa nature open-source implique une responsabilité directe côté utilisateur, notamment en matière de RGPD.
Qui gagne selon votre besoin ?
Pour un RAG de prod ultra-rapide
Si vous construisez un pipeline RAG en production, où l’objectif est de crawler massivement et rapidement des sites entiers (documentation technique, articles de blog, pages produit), Firecrawl est le candidat naturel. Il combine scalabilité, vitesse et formatage LLM-ready. Vous pouvez l’intégrer directement dans vos flux de traitement sans réécrire le moindre parseur.
C’est aussi le meilleur choix si vous avez des contraintes de coût au volume, ou si votre architecture nécessite un composant robuste, orchestrable, monitoré et résilient.
Pour un projet exploratoire à haute valeur ajoutée
Si votre objectif est d’extraire des données ciblées, de manière intelligente, voire de générer automatiquement des scripts de scraping, alors ScrapeGraphAI est imbattable. Il excelle dans les cas où chaque page est unique, où le balisage HTML n’est pas fiable, ou lorsque vous voulez simplement écrire un prompt pour “lire” une page comme un humain.
C’est l’outil rêvé pour des projets ponctuels, des proofs of concept, ou des extractions à forte valeur métier (prix de produits, chiffres clés, données réglementaires, etc.).
Pour une veille ou extraction continue intelligente
ScrapeGraphAI permet de configurer des pipelines de scraping intelligents : surveiller plusieurs sites web, agréger des données spécifiques, générer des résumés ou synthèses. Si votre besoin évolue vite et que vous préférez décrire ce que vous cherchez plutôt que coder, alors son approche “prompt-to-graph” vous fera gagner un temps précieux.
Cependant, attention au coût des tokens LLM si l’usage devient intensif. Firecrawl reste plus rentable pour de la veille massive low-cost.
Conclusion : Firecrawl ou ScrapeGraphAI, lequel choisir en 2025 ?
Le choix entre Firecrawl et ScrapeGraphAI reflète une décision stratégique : optimiser pour la vitesse, ou optimiser pour la pertinence.
Firecrawl est l’outil idéal pour les projets à grande échelle, où la performance brute, la scalabilité et l’intégration immédiate aux workflows RAG comptent plus que la finesse d’extraction. Son approche orientée “crawl massif” permet d’alimenter rapidement des bases de connaissances prêtes pour les LLM, à coût maîtrisé.
ScrapeGraphAI, quant à lui, s’impose quand il s’agit de comprendre et extraire des données précises, avec le moins d’effort humain possible. Sa logique orientée prompts en fait un compagnon idéal pour des tâches ponctuelles à forte valeur ajoutée, ou pour automatiser des veilles intelligentes.
En résumé :
Besoin de volume, vitesse, Markdown prêt à indexer ? Choisissez Firecrawl.
Besoin de précision, flexibilité, scraping piloté par l’IA ? Optez pour ScrapeGraphAI.
Dans une logique IA-first, le futur des workflows RAG passe probablement par une hybridation : utiliser Firecrawl pour la couverture large, et ScrapeGraphAI pour zoomer avec finesse sur les pages qui comptent. À vous de composer le duo gagnant.
👉 A lire aussi :
-> Comment choisir les meilleurs outils d’exploration web RAG
Vous hésitez encore ou avez besoin d'un accompagnement spécifique, notre équipe est à votre écoute
Partager avec
💙 Merci d'avoir parcouru l'article jusqu'à la fin !
Romain DE LA SOUCHÈRE
Lead Developer, Expert Cloud et DevOps
Romain DE LA SOUCHERE est un ingénieur passionné par la data et l’innovation. Après plus de 11 ans d’expérience, dont plusieurs années comme Lead Developer sur des solutions Smart Building à haute performance, il a rejoint Formations Certifiantes en Data Science, IA & Azure | DataScientist.fr pour transmettre son savoir-faire en data engineering, cloud Azure et IA générative.